
 Tue, Jan 20, 2026
Tue, Jan 20, 2026Decision-Time Guidance: Keeping Replit Agent Reliable
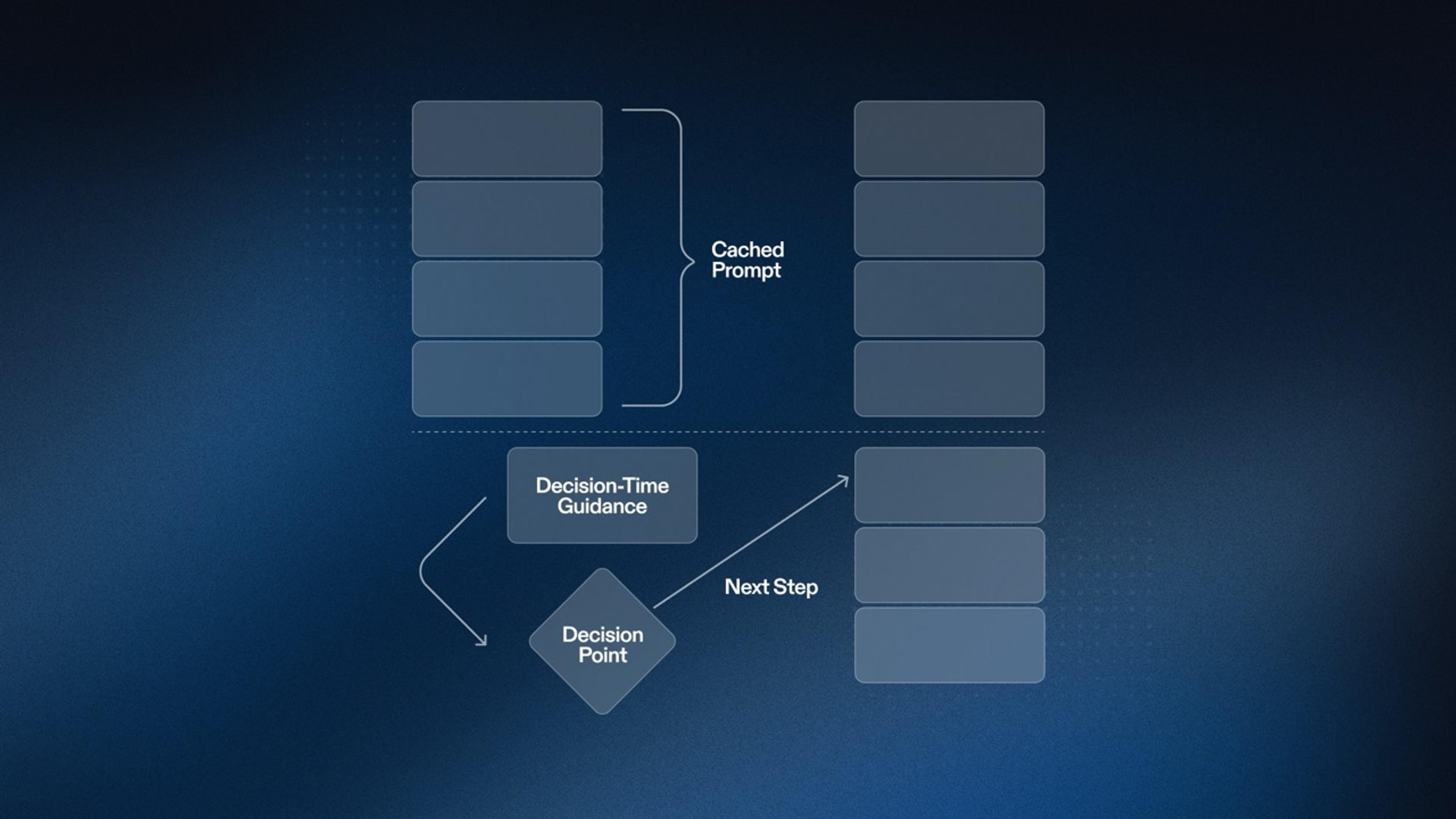
At Replit, we want to give our users access to the most powerful agentic coding system in the world—one that amplifies their productivity and minimizes the time from idea to product. Today, Replit Agent tackles more complex tasks than ever before. As a result, average session durations have increased and trajectories have grown longer, with the agent completing more work autonomously. But longer trajectories introduce a novel challenge: model-based failures can compound, and unexpected behaviors can surface. Every trajectory is unique, so static prompt-based rules often fail to generalize—or worse, pollute the context as they scale. This demands a new approach to guiding the agent when failures are detected. Our insight: the execution environment itself can be that guide. The environment already plays a critical role in any agentic system—but what if it could do more than just execute? What if it could provide intelligent feedback that helps the agent course-correct, all while keeping a human in the loop? In this post, we discuss a set of techniques that have proven effective on long trajectories, significantly improving Replit Agent across building, planning, deployment, and overall code quality—while keeping costs and context in check. The Problem with Static Prompts on Long Trajectories System prompts and few-shot examples are the classic way to steer an agent by specifying intent and constraints up front. In practice, many production agents also rely on execution-time scaffolding—task lists, reminders, and other lightweight control signals—that are updated as the agent observes tool output and responds to user input.
 Wed, Mar 5, 2025
Wed, Mar 5, 2025Using Tvix Store to Reduce Nix Storage Costs by 90%
For the past few years, Replit has been using Nix to serve packages/dependencies and provide consistent development environments to our users. Nix on Replit allows users to have access to a large number of packages and libraries that can be seamlessly integrated into a user's project. Motivation In order to quickly serve thousands of packages to our users, we attach a large Nix store persistent disk to all development containers serving Replit apps. While this approach has worked well for a while, this persistent disk grows with every subsequent NixOS release (eventually reaching a size of 20Tb). When considering ways to reduce the size of this disk, one important constraint was to never remove store paths from the cache. Project that depend on packages in older Nix channel releases could still link to these store paths, so in order to maintain backwards compatibility those store paths must remain. Tvix Store Tvix is a new modular implementation of Nix that contains a series of components that can be used individually. One of these components is the Tvix store. tvix-store is a Nix store implementation backed by the tvix-castore. The tvix-castore manages blobs (file contents) and directory info (file metadata, like names, permissions, etc). tvix-store manages nix path info metadata, effectively creating a mapping of Nix store paths to tvix-castore contents.
 Tue, Nov 26, 2024
Tue, Nov 26, 2024So you suspect you have a memory leak...
Programming languages with Garbage Collectors are fantastic! You no longer need to keep track of every single piece of memory that your program needs to run and manually dispose of them. This also means that your programs are now immune to bugs like double-free (accidentally freeing a resource more than once, leading to crashes or security vulnerabilities) and most memory leaks (accidentally not freeing a resource, leading to crashes by running out of memory). But it is still possible to have a memory leak. Consider this TypeScript snippet: The global cache makes fibonacci fast, but it relies on a global cache that has no way of being cleared, so it will always accrue memory when it is called with larger and larger numbers. Slowly but surely. At some point during the development of Replit Agent, one of our engineers spotted the following graph in our dashboard: We had strong evidence that the agent processes were running out of memory roughly once an hour, and that likely means a memory leak. Since we were constantly serializing each agent process’ state to its Repl, we were able to recover without losing any data, but that meant that we had to re-run several LLM calls, and those tend to add up. This also implies that users would sometimes see some spurious slowdowns, so that was suboptimal too.
 Wed, Aug 14, 2024
Wed, Aug 14, 2024How Replit makes sense of code at scale
Data privacy and data security is one of the most stringent constraints in the design of our information architecture. As already mentioned in past blog posts, we only use public Repls for analytics and AI training: any user code that's not public — including all enterprise accounts — is not reviewed. And even for public Repls, when training and running analyses, all user code is anonymized, and all PII removed. For any company making creative tools, being able to tell what its most engaged users are building on the platform is critical. When the bound of what’s possible to create is effectively limitless, like with code, sophisticated data is needed to answer this deceivingly simple question. For this reason, at Replit we built an infrastructure that leverages some of the richest coding data in the industry. Replit data is unique. We store over 300 million software repositories, in the same ballpark of the world’s largest coding hosts like GitHub and Bitbucket. We have a deeply granular understanding of the timeline of each project, thanks to a protocol called Operational Transformation (OT), and to the execution data logged when developers run their programs. The timeline is also enriched with error stack traces and LSP diagnostic logs, so we have debugging trajectories. On top of all that, we also have data describing the developing environment of each project and deployment data of their production systems. It’s the world’s most complete representation of how software is made, at a massive scale, and constitutes a core strategic advantage. Knowing what our users are interested in creating allows us to offer them focused tools that make their lives easier. We can streamline certain frameworks or apps. Knowing, for instance, that many of our users are comfortable with relational databases persuaded us to improve our Postgres offering; knowing that a significant portion of our most advanced users are building API wrappers pushed us to develop Replit ModelFarm. We can also discover untapped potential in certain external integrations with third-party tools, like with LLM providers. It informs our growth and sales strategy while supporting our anti-abuse efforts. And, of course, it allows us to train powerful AI models. Ultimately, this data provides us with a strong feedback loop to better serve our customers and help them write and deploy software as fast as possible. While all this is true, it’s also not an easy feat. Several challenges come with making the best use of this dataset, and all stem from the astronomical magnitude of the data. We store on Google Cloud Storage several petabytes of code alone, and our users edit on average 70 million files each day, writing to disk more than 1PiB of data each month. This doesn’t even consider OT data, and execution logs, both in the same ballpark for space taken and update frequency. Going from this gargantuan amount of raw programming files to answering the question “What is being built?”, all while being mindful of user privacy, is, well, hard.
 Mon, Mar 18, 2024
Mon, Mar 18, 2024More Reliable Connections to Your Repls
At Replit, session success rate is one of our service level objectives (SLOs). This means that any legitimate incoming request from a client should always be successfully connected to its target Repl. Failure to do so is a bad user experience. To abstract away intermittent infrastructure failures when you connect to a Repl, we use a reverse WebSocket proxy between the user’s client and the remote VM hosting Conman, our container manager that runs all Repls in a container. The high-level view of this proxying looks something like this: In the above diagram, Regional Goval Cluster represents our backend, which is sharded per region for scale and to prevent cross-region latency and egress costs. You can read more about it in this blog post. The diagram illustrates that the reverse WebSocket proxy can attempt a retry if any failures occur during the connection setup with Conman. The proxy is alive throughout the connection and transfers data back and forth between the client and the user’s Repl. The problem Everything seems architecturally sound here, so what was the problem? Conman, technically our container manager and responsible for running Repls in containers on GCE VMs, also doubled up as our reverse WebSocket proxy. Here’s what our architecture and overall flow used to look like:
 Wed, Feb 14, 2024
Wed, Feb 14, 2024Sharding Infrastructure: The Regional Goval Project
The main task of the infrastructure team at Replit is to ensure your Repls run well. A Repl can be thought of as a Linux container with a filesystem. To run Repls, we need to take care of several pieces of infrastructure: Virtual machines to run Repl containers on Databases to keep track of container and VM states Cloud storage to store Repl contents Reverse proxies to route HTTP requests
 Thu, Dec 21, 2023
Thu, Dec 21, 2023Dec 12 Incident Update: Secrets and repl.co Static Hosting Unavailable
Between Dec 12 and Dec 16, Secrets in interactive Repls and files in our legacy repl.co static hosting were unavailable. The root cause was a configuration push to GCS storage that was misinterpreted as a request for all the files to be evicted from storage. Deployments and Secrets in Deployments were unaffected. We have since recovered all known user Secrets and instituted new data retention procedures in our storage systems to ensure that this issue doesn’t reoccur. This will allow us to have a faster recovery going forward. This post summarizes what happened and what we're doing to improve Replit so that this does not happen again. Technical details Here is the timeline of what happened: On Dec 11, we pushed an update to our Terraform configuration for the Google Cloud Storage lifecycle of several buckets. This included a bucket where Secrets, legacy repl.co static hosting, and some Extensions are stored. This was done in an attempt to automatically delete any noncurrent object to save space. These buckets had object versioning enabled beforehand, and the update inadvertently set the daysSinceNoncurrentTime field to zero. Setting this field to zero caused the request to be interpreted as equivalent to setting age to zero, because it also missed explicitly setting isLive to false. This behavior was unexpected, which is tracked in the underlying Terraform provider in a GitHub issue. We quickly discovered the issue, and between Dec 12 and Dec 16 a recovery process was able to recover all known user Secrets.
 Wed, Oct 4, 2023
Wed, Oct 4, 2023Sep 29 Incident Update: Read-Only Repls
On Sep 29, we had a period of about 2.5h from 14:00 to 16:30 (Pacific Time), in which an incomplete build was pushed to our infrastructure that handles storing Repl data. This caused Repls opened during that time window to become read-only or stop working. Any Repl not opened during that timeframe was not affected. We have addressed the root cause, recovered 98% of the affected Repls, and continue to work on recovering the remaining 2%. We understand that your data not being available is unacceptable for both you and your users. This post summarizes what happened and what we're doing to improve Replit so that this does not happen again. Technical details Here is the timeline of what happened, all times in Pacific Time: On July 19, we released a new storage system. This works by recording "manifests" that represent snapshots of the filesystem at a specific point in time, and the manifests point at blocks that contain the users' data. This enables fast and efficient Repl forking. To improve that system, we’ve been working on a change to make obtaining filesystems and saving changes faster by batching commits and executing them asynchronously. This change was being vetted in a test cluster and we were diagnosing failure modes with writing manifests and running garbage collection that caused data corruption. On Sep 29 at 14:00, as part of attempting to deploy additional logging statements to the test cluster, the new (unfinished) feature was inadvertently deployed to production clusters. This is when the outage began. Any Repl loaded with this build could have potentially been put into an error state showing “read only filesystem” or other I/O errors.
 Mon, Aug 7, 2023
Mon, Aug 7, 2023Expand possibilities on Replit with Expandable Storage
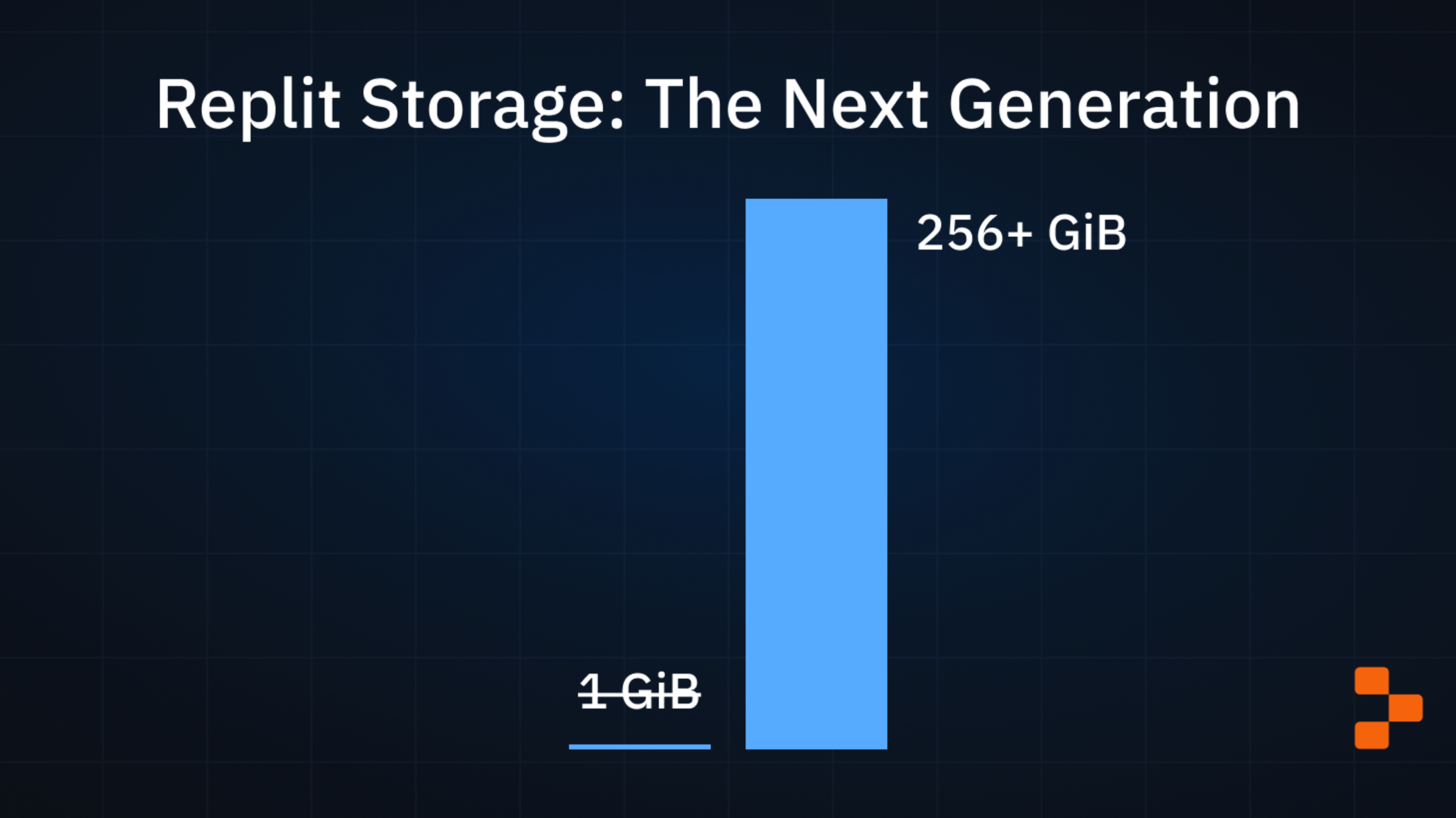
We're excited to roll out Expandable Storage, Replit's new storage infrastructure making the 1 GiB per-Repl restrictions a thing of the past. A couple weeks ago, we announced the next generation of storage that will allow Repls to reach 256 GiB. This change also included higher account-wide storage limits for everyone: Free plan gets 10 GiB Hacker plan gets 20 GiB
 Sun, Jul 30, 2023
Sun, Jul 30, 2023Replit Deployments: 3x Faster and Even More Features
In April, we released Replit Deployments, the fastest way to go from software idea to production. We rebuilt our application hosting infrastructure for production-grade applications thanks to your feedback. In this post, we’ll highlight upgrades, bug fixes, and improvements to Deployments since initial release in April. Replit Deployments > Always On Replit Deployments is a better and more reliable than our previous hosting option, Always On: Your app is hosted on Google Cloud VMs making it more reliable and stable. Isolated VM resources for your app will give you improved security and performance. Control when you release to users so you can fix your app without breaking production.
 Wed, Jul 19, 2023
Wed, Jul 19, 2023Replit Storage: The Next Generation
Repls today allow 256+ GiB of storage space, up from a historical 1GiB limit. This post is about the infrastructure that enabled that change. Historically Replit limited files in each Repl to 1 GiB of storage space. The 1 GiB limit was enough for small projects, but with the advent of AI model development and with some projects needing gigabytes worth of dependencies to be installed, 1 GiB is not enough. We announced on Developer Day that we were rolling out the infrastructure to unlock much larger Repls, and this is the first part of that. Read on to see why that limit existed in the first place, what changed, and how we pulled it off.
- Fri, May 19, 2023
May 18 Replit downtime
Yesterday, we had a period of about 2h from 11:45 to 13:56 (Pacific Time) in which all users were unable to access their Repls through the site. We have addressed the root cause, and the system is now operating normally. We know a two-hour downtime is not acceptable for you or your users. This post summarizes what happened and what we're doing to improve Replit so that this does not happen again. Technical details Here is the timeline of what happened, all times in Pacific Time: In 2021, we changed the way that configuration is pushed to the VMs that run Repls and streamlined multiple kinds of configurations. During this migration, a latent bug that we had not hit was introduced. When we tried to see if a configuration kind had been updated, we acquired a Golang RwMutex for reading, but if there was not a handler for that configuration kind, the read-lock would not be released. Golang's RwMutex are write-preferring, so acquiring multiple read-locks is allowed as long as there are no goroutines attempting to acquire a write-lock. When that happens, it will cause any future read-locks to block. On May 16, 2023,we introduced a new configuration kind, but we did not add a handler, which means that from this point on we were leaking read-locks, but the system was able to make progress.
 Tue, Apr 18, 2023
Tue, Apr 18, 2023How to train your own Large Language Models
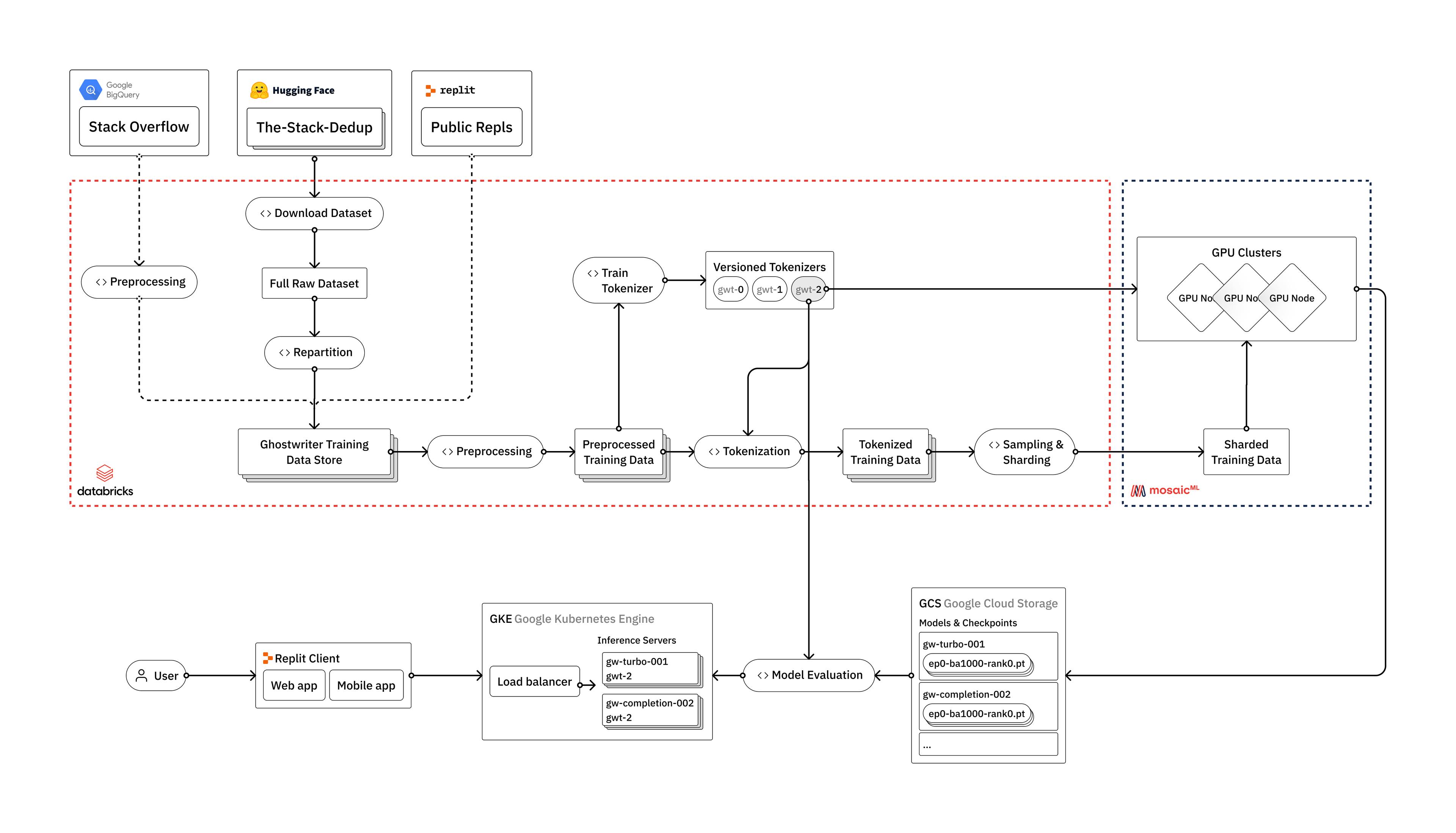
Learn how Replit trains Large Language Models (LLMs) using Databricks, Hugging Face, and MosaicML Introduction Large Language Models, like OpenAI's GPT-4 or Google's PaLM, have taken the world of artificial intelligence by storm. Yet most companies don't currently have the ability to train these models, and are completely reliant on only a handful of large tech firms as providers of the technology. At Replit, we've invested heavily in the infrastructure required to train our own Large Language Models from scratch. In this blog post, we'll provide an overview of how we train LLMs, from raw data to deployment in a user-facing production environment. We'll discuss the engineering challenges we face along the way, and how we leverage the vendors that we believe make up the modern LLM stack: Databricks, Hugging Face, and MosaicML. While our models are primarily intended for the use case of code generation, the techniques and lessons discussed are applicable to all types of LLMs, including general language models. We plan to dive deeper into the gritty details of our process in a series of blog posts over the coming weeks and months. Why train your own LLMs?
 Tue, Apr 11, 2023
Tue, Apr 11, 2023Replit Deployments - the fastest way from idea → production
After a 5 year Hosting beta, we're ready to Deploy. Introducing Replit Deployments Today we’re releasing Replit Deployments, the fastest way to go from idea to production in any language. It’s a ground up rebuild of our application hosting infrastructure. Here’s a list of features we’re releasing today: Your hosted VM will rarely restart, keeping your app running and stable. You’re Always On by default. No need to run pingers or pay extra.
 Wed, Apr 5, 2023
Wed, Apr 5, 2023Hackers, Pros, and Teams users can now code for hours without restarts
Stay Connected Starting today, all users on Hacker, Pro, or Teams plans will see a 10x reduction in container restarts while coding in the Workspace. Previously, you would experience a restart at least once an hour. Now you can code for multiple hours straight without restarts. Deep work can stay uninterrupted and you can keep programs running longer while you build. Repls are computers that live in the cloud. One of the most painful experiences with a cloud computer is losing your network link. Sometimes your network flakes out and things need to reconnect. But the worst version is when your Repl restarts. There are lots of reasons why this can happen. In the background, your container has stopped or died, and our infrastructure quickly starts up a new one to put you in. You can simulate this by typing kill 1 in the Shell.