The main task of the infrastructure team at Replit is to ensure your Repls run well. A Repl can be thought of as a Linux container with a filesystem. To run Repls, we need to take care of several pieces of infrastructure:
- Virtual machines to run Repl containers on
- Databases to keep track of container and VM states
- Cloud storage to store Repl contents
- Reverse proxies to route HTTP requests
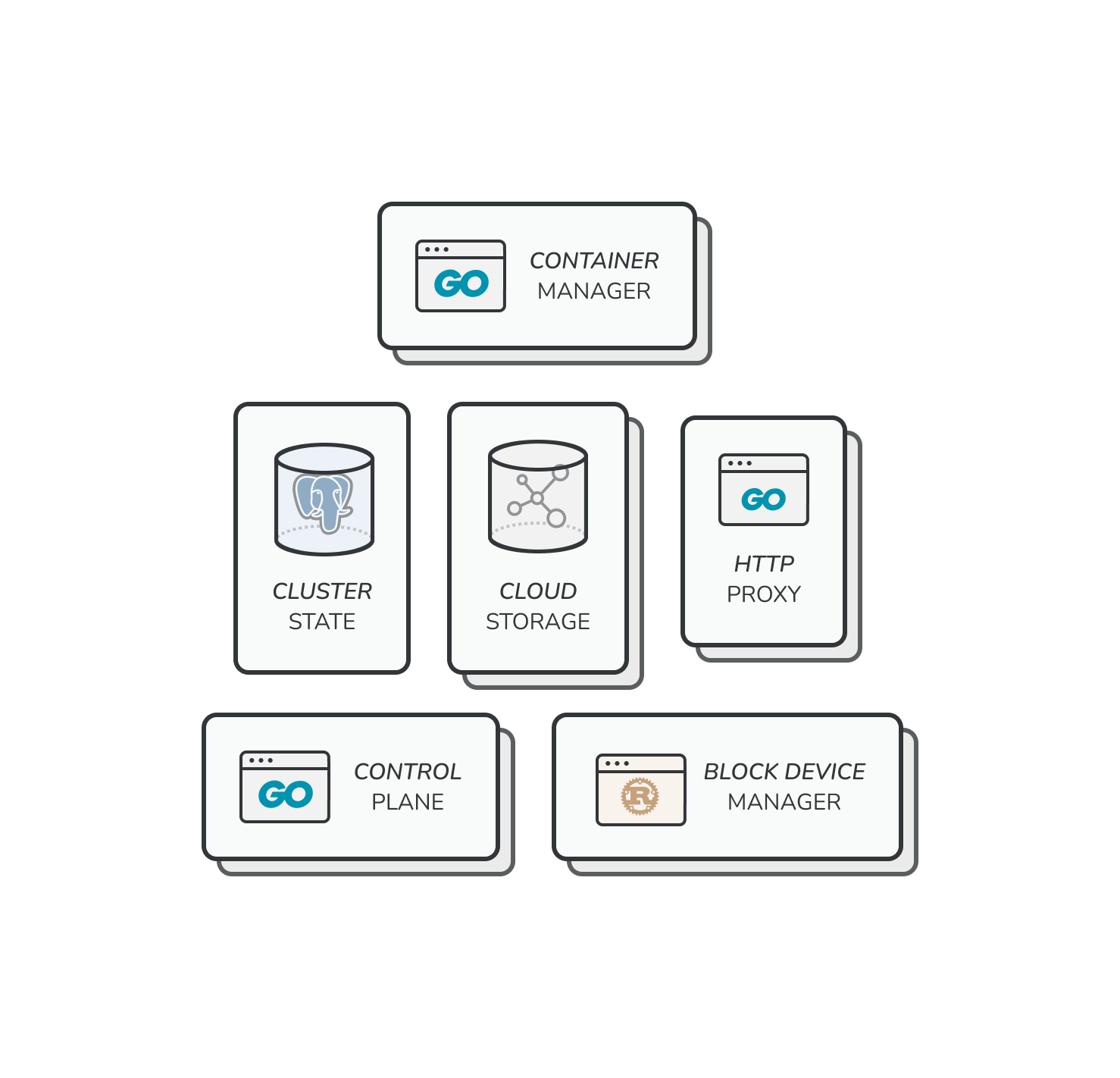
These components roughly constitute what we call Goval, the set of infrastructure that runs Repls. What is the best way to organize these pieces? Given that we’re regularly running on the order of tens of thousands of Repls at any one time, this is no small challenge. We want to arrange things in such a way that:
- Guarantees good utilization of all parts of the system
- Copes well with scale
- Minimizes and isolates faults
Over the years, we’ve learned a lot about how we can organize cloud infrastructure for Repls and the tradeoffs involved.
A brief history of Replit infrastructure
Up until three years ago, we operated the whole infrastructure in a single failure domain. This works fine if you have low enough traffic, but faults can quickly cascade and take down your entire system. In 2021, we took on the effort of partitioning our infra into multiple clusters. A cluster can be visualized as an isolated unit of operation required to run Repls. In most cases, if a single cluster fails, the other clusters remain unaffected. We also developed the infrastructure necessary to track which clusters Repls live in and how to handle transfers between clusters.
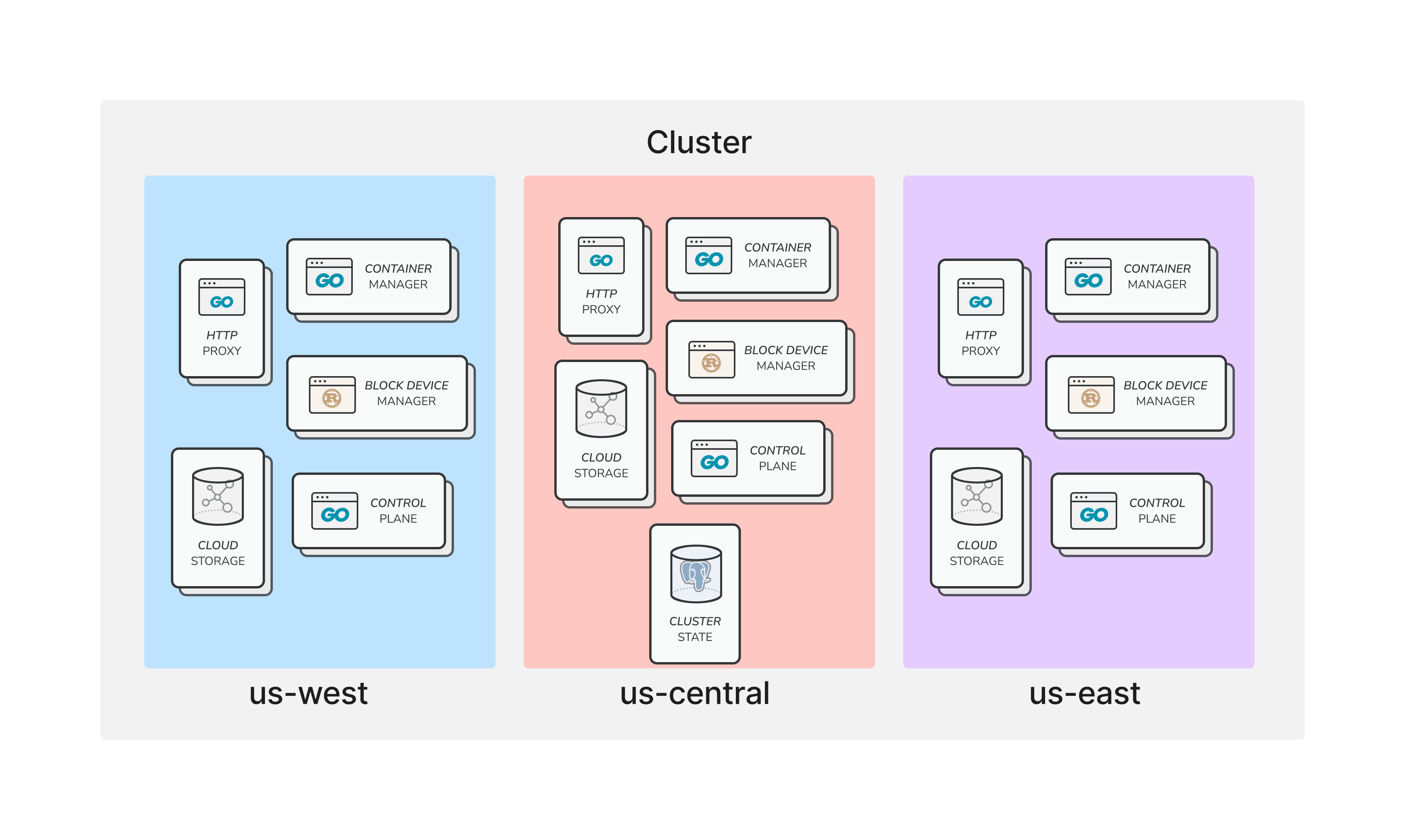
We initially split Repls across clusters on a user membership basis. Having multiple failure domains was a big win for overall reliability and limiting the scope of cascading failures. Over time, we noticed some flaws in our partitioning scheme. We ended up with a free-tier cluster that was much larger than the other clusters. Each cluster also had infrastructure spread throughout the continental United States (multiple US regions in GCP). This caused highly inefficient situations where a single container session could invoke connections across multiple Google Compute regions. Also, the brains of the cluster had to live in a single region (us-central1), meaning that an outage in that region would cause the whole cluster to malfunction.
We tried a new architecture when creating new clusters in Asia as part of the Worldwide Repls project. To solve the problem of having massively unbalanced clusters, we instead imposed a constraint that clusters be uniformly sized. Instead of using membership status to distribute Repls, we used consistent hashing to ensure an even distribution while keeping the possibility of adding/removing clusters in the future.
That experiment informed our decisions on our next large undertaking: reworking the entire Replit infrastructure. Here are some of the motivations behind this project:
- Using uniform clusters makes them easier to provision, manage, and operate than clusters with different characteristics.
- Having more failure domains means users will experience fewer problems when a single cluster fails.
- Having smaller failure domains, in turn, means that the types of faults you see with scale are less likely to happen. As a result, we get better reliability.
- We wanted to rework how we manage our infrastructure with IAC. The goal was to unify infrastructure and configuration management and make it easy to create and deprovision clusters on demand.
Making it easy to provision clusters through code also unlocks the possibility of creating single-tenant projects with dedicated single-tenant clusters for enterprise customers.
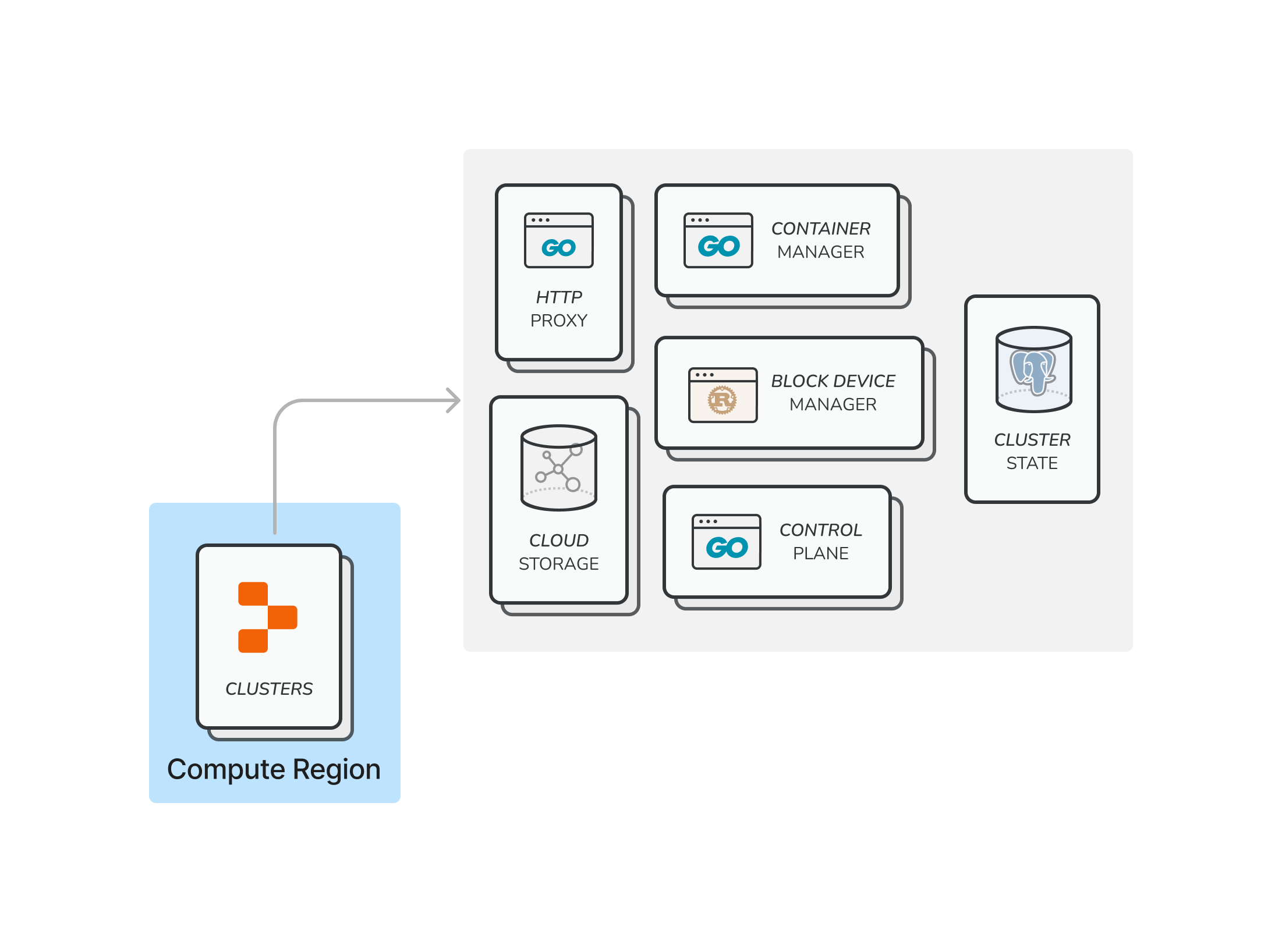
We named this project Regional Goval, because the new clusters would be contained in a single region—a modest name for a significant effort.
Let’s dive into the details of how we accomplished this.
Infrastructure as code
Up until this point, we managed our infrastructure with a large chunk of Terraform with some Ansible sprinkled in. As our platform grew, we encountered a few problems with this setup:
- We had one large Terraform state for most of the infrastructure. Running
terraform plantook a long time. - Due to the large Terraform state, we ended up with some tightly coupled dependencies. This made it hard to make changes without affecting much of the infra.
- Even with extensive use of modules, we had to develop a bespoke Terraform code generation tool to reduce code duplication. This was hard to work with.
- Some configurations lived outside the Terraform repository. For instance, instance group sizes were set in an Ansible configuration file.
In our new cluster design, we wanted to rely heavily on standard modules of infrastructure that can be reused and provisioned on a configuration basis. We also wanted to take the chance to start fresh and make sure we correctly codified all our infrastructure in one place. For Regional Goval, we decided to try out CDK for Terraform, using Typescript as the programming language. We figured that CDK provided the tools we needed to avoid one large Terraform state for the type of project organization we wanted to use. Typescript is a high-level language with great tooling and support, which we thought we lacked in HCL.
We started by writing CDK code for each piece of infrastructure, slowly building up reusable blocks as we went along. We ended up with a setup that we’re much happier with. The burden of making minor changes is now significantly reduced. This means that we’re making far fewer manual alterations than before. Another positive point is that we built modules that allow us to provision new clusters easily. Not only that, we can also easily create clusters in separate GCP projects if needed. This unlocks the possibility of creating completely separate environments and single-tenant clusters. All while avoiding the original issue with the unwieldy Terraform state.
Out with the old: transferring traffic to the new clusters

With the new infra in place, it was time to test it and incrementally release it to users. There are some tricky aspects to this migration:
- We didn't want to have any downtime. Users should be able to connect to Repls normally during the large-scale migration. This means that transferring individual Repls should be nearly instantaneous. It also means that we must ensure the new clusters are fully operational before bringing users in.
- Even if we’re confident that the new clusters are fully functional, we need to maintain the capability of reverting to the old clusters in case an emergency happens. This significantly reduces risk in a gradual rollout.
- There are an astoundingly large number of Repls. It’s infeasible, both in cost and time, to transfer all of them upfront. We needed a strategy to keep these Repls in storage and transfer them whenever users need them, even if the old clusters no longer exist.
Given these constraints, we decided on a three-step migration procedure:
- Stop creating Repls in the old clusters.
- Once all new Repls are created in the new clusters, slowly reduce the amount of new sessions from existing Repls that spawned in the old clusters. This can be done by lazily transferring Repls from old clusters as connection requests come in.
- Once we’ve drained all sessions from old clusters, deprovision the old clusters while keeping untransferred Repls in storage.
The initial clusters project required us to develop primitives for transferring Repls across clusters. Our experience migrating users to new clusters for the Worldwide Repls project proved very useful. In particular, we refined the lazy transfer mechanism from that project.
We accomplished the incremental migration with feature flags. We had separate flags for controlling the creation of Repls in new clusters and for easing the on-demand, lazy transfer of existing Repls to new clusters. We monitored key statistics such as container count and Repl session failure rate throughout this process. The issues we encountered during this process were mostly due to old assumptions about changing clusters, and were contained to a small blast radius. This allowed us to accomplish the migration with minimal impact.
Shutting down old clusters
Once all traffic went to the new clusters, we were ready to decommission the old clusters. This was mostly a combination of deleting Terraform code with some manual intervention to address tricky dependencies. Turns out that in many cases, creating cloud infrastructure is a lot easier than deleting it!
What's next?
The Regional Goval project was a massive undertaking. Not only did we have to rework crucial parts of the infrastructure completely, but we also had to migrate all running Repls to new compute clusters without visible interruptions in service. The results have been unequivocal: the new infrastructure is easier to operate and reason about, and reliability has also vastly improved.
The exciting part about this project is that we now have a readily reusable abstraction of Replit clusters as code. Besides the gains in reliability and developer productivity, we’ve taken a significant step up in the level of abstraction we’re operating in.
Are you interested in cloud computing and distributed systems? Come work with us to create the next-generation cloud development environment!