
During the ReplCon 2022 keynote, we announced that we were going to geo-distribute our infrastructure so that your Repls are much faster when accessed outside of the United States. The speed of electrons / light in a medium is a fundamental speed limit. Most of our users are several thousand kilometers away from the data centers where we host Repls (currently limited to the United States), so the round trip from them to the users' homes is going to necessarily take several hundred milliseconds just to traverse the series of tubes that is the Internet. Today, we have finished the first milestone to make this a reality, and that comes with some pretty neat side-effects!
The control / data plane separation
Up to this point, our infrastructure was designed in a way that allows for horizontal scalability: being able to have more capacity to run Repls by adding more VMs to our infrastructure. This allows us to quickly react to having more users at certain times of day without making any code changes, and is built upon having a Load Balancer that routes requests to connect to a container using the WebSockets protocol to individual VMs in our infrastructure.
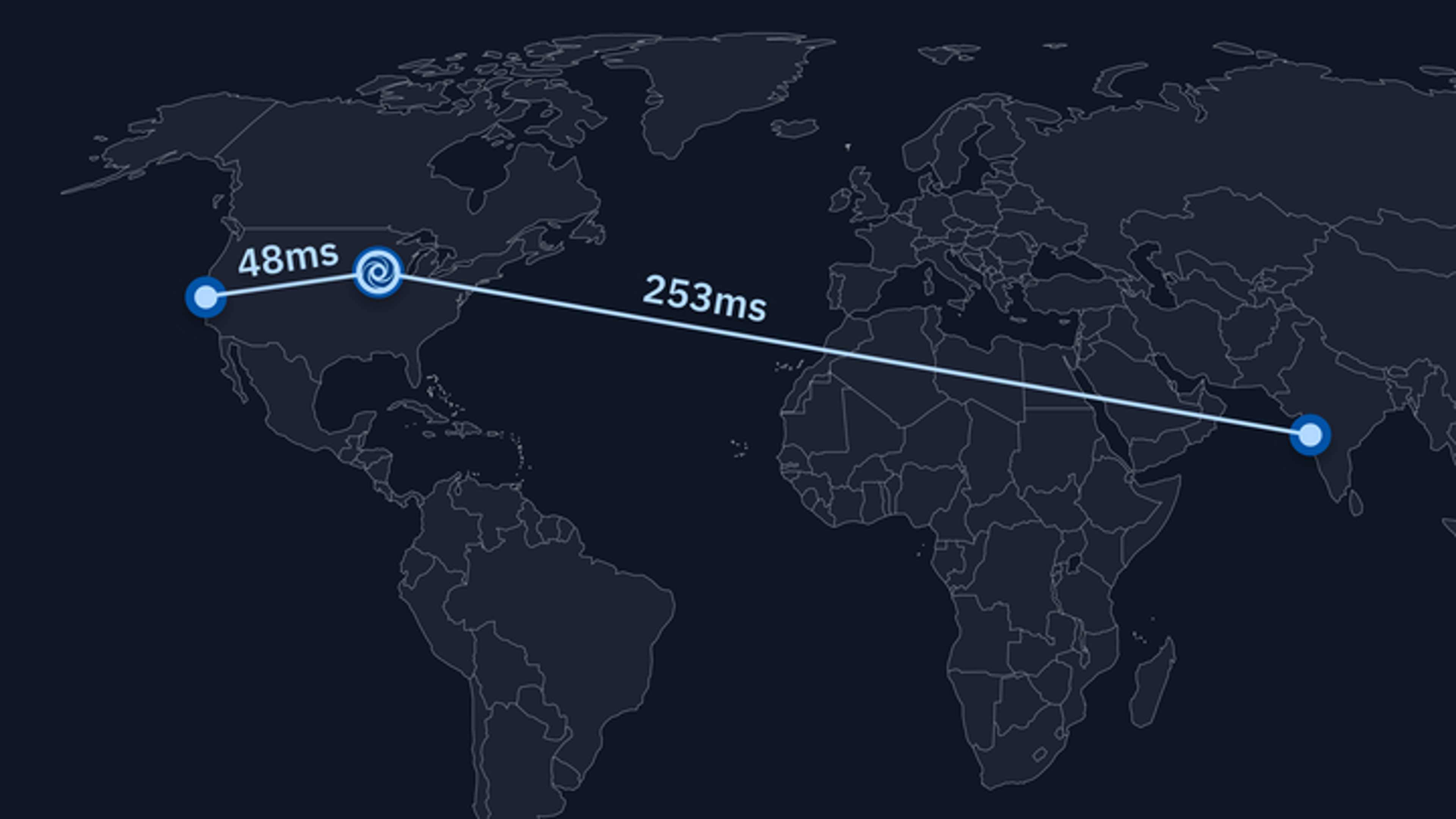
Some of you might remember that we had announced global routing last year, which we achieved by having a small set of servers in Mumbai, India. That worked well during testing, but after enabling it for everybody we discovered an interesting edge case: since the Load Balancer is the component that decides where any WebSockets connection goes and we have little control over that whole process, sometimes the India servers were a bit busier than servers elsewhere and the Load Balancer decided to route a connection to the United States. But what if this was a multiplayer Repl, or a reconnect to a Repl that was already running? In those cases, the VM where the request lands performs a transparent proxy of the WebSockets connection to the VM where the Repl is actually running. So now users would have to connect to a server in the United States (which was the old "normal"), but then that server had to talk to a server in India, which added an unnecessary ~250ms worth of roundtrip to the previous behavior. We had accidentally made things slower! Sadly, we had to revert this change 😢.
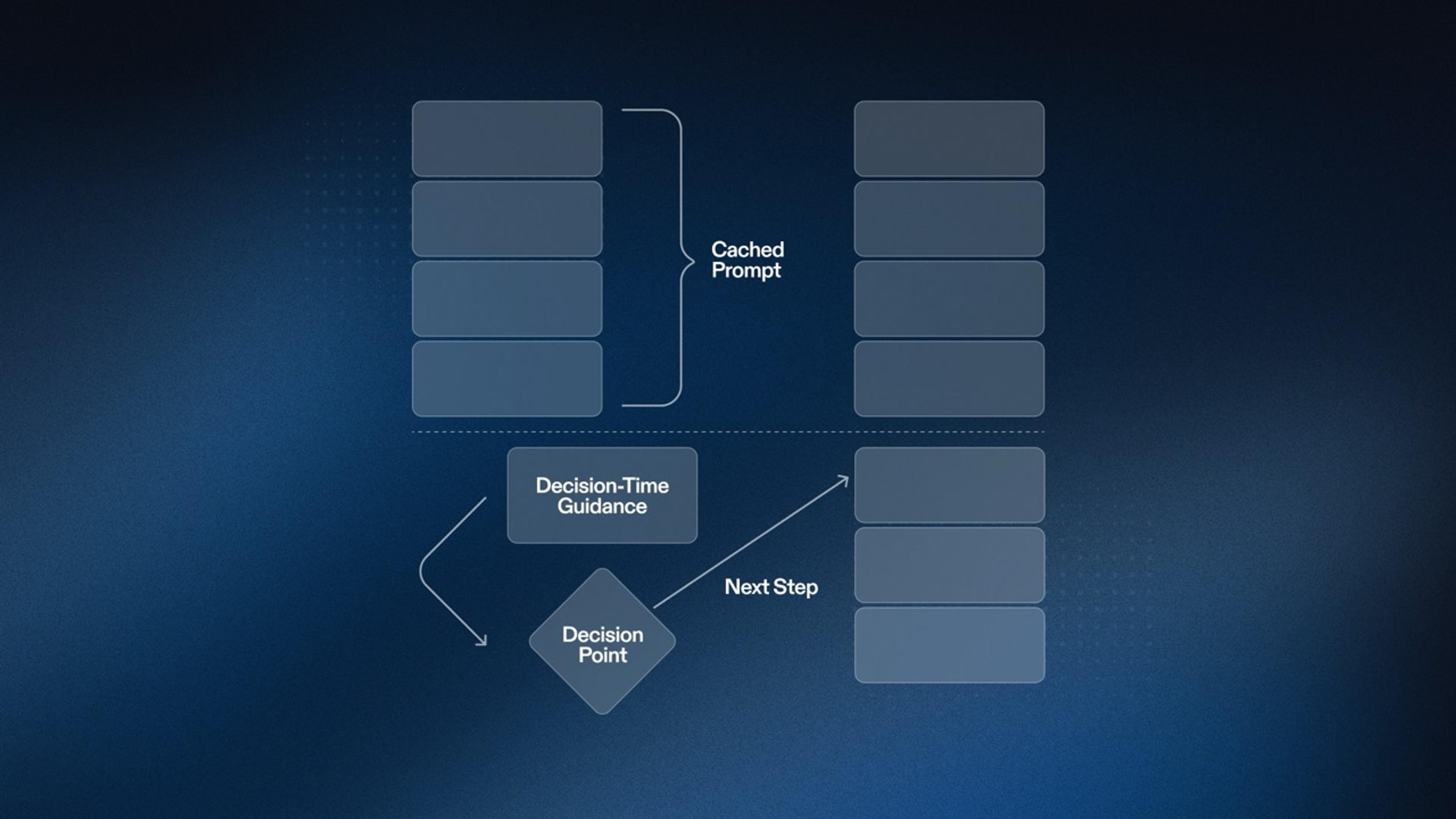
So back to the drawing board we go. What became obvious is that we had to make changes such that the Load Balancer was not the source of truth of where Repls are placed. Enter the Control Plane. In Networking, there is a distinction between what are called Control and Data Planes: where the Control Plane is concerned with making changes to the network to make sure that packets go to their destination in the best way possible at that moment, and the Data Plane is the part of the system that actually moves the internet packets (a.k.a. the data). There is also the Management Plane, which is analogous to the Control Plane but manages other non-networking systems. So for us, we wanted to have a Control / Data Plane separation to clearly distinguish making modifications to the shape of the system: making a Repl start / stop in a particular VM vs. the WebSockets communication between the Linux container and the Workspace.
A new abstraction to build upon
Once we decided we were going to be making changes to the system, we thought about what other use cases and user-visible improvements we could unlock with this new tool. To start, now that we need to have a central system that has a consistent view of the infrastructure, we also needed to clean up the data layer that the container-running machines were using. Previously, this was done by having a massive Redis instance for every user cluster, available directly to each machine running user code. This decision to not have an ACID-compliant store made a lot of sense back when it was made, since Replit's scale was significantly smaller. But we have outgrown the data model allowed by Redis, and it had started to hamper our growth: a single Redis instance meant that servers further away from the United States would necessarily have significantly higher latencies on every roundtrip to the data store, and the non-transactionality of Redis meant that it was difficult to get a highly consistent view of the state of any individual Repl. These two things (together with some other long-standing bugs) caused some data races that resulted in inconsistencies in our infrastructure: it was possible for a single Repl to have two containers, which leads to data loss!
With the central Control Plane, we are now able to co-locate it with the data storage (which we have chosen to be PostgreSQL). This way we can build higher level operations that mutate the state of several aspects of a Repl at once in a single network roundtrip to the Control Plane service. Also, this means that we can also request multiple bits of metadata in a single network roundtrip!
Normally, software rewrites are seen as a something you should never do. But in this case it turned out to be a good decision, because this rewrite had a pretty clear purpose (unlocking a set of future functionality that was impossible to achieve with the old system), and we were also able to plan this in a way to deliver value incrementally.
Rolling out a huge refactor
With a design in hand, it was time to decide how to actually roll it out while minimizing regressions. To do that, we decided to use the strangler fig pattern, in which a "legacy system" (the current implementation) and a new system that have the same interface but different implementations are called behind an abstraction layer that calls both systems in parallel and throws one response away, with a lot of dynamic runtime flags to change this behavior and shut either system down in case of an emergency. This allowed us to build the implementation one API at a time, and since we had the responses of both systems, we could diff them to spot any inconsistencies to build confidence of correctness even in edge cases. This gradual enabling of the system also allowed us to better understand the resources that were needed to handle the expected load at the end, and compare the observed behavior with some initial synthetic load tests that we had written in preparation.
Another advantage of doing it this way is that this allowed the data set of both databases to converge to the same values: the new system had an initial import from a backup of the old system, and from then on, it started seeing all the same requests as the old system. And since the number of inconsistencies was trending in the right direction (towards zero) as we kept implementing more APIs, we were confident that no data was being lost.
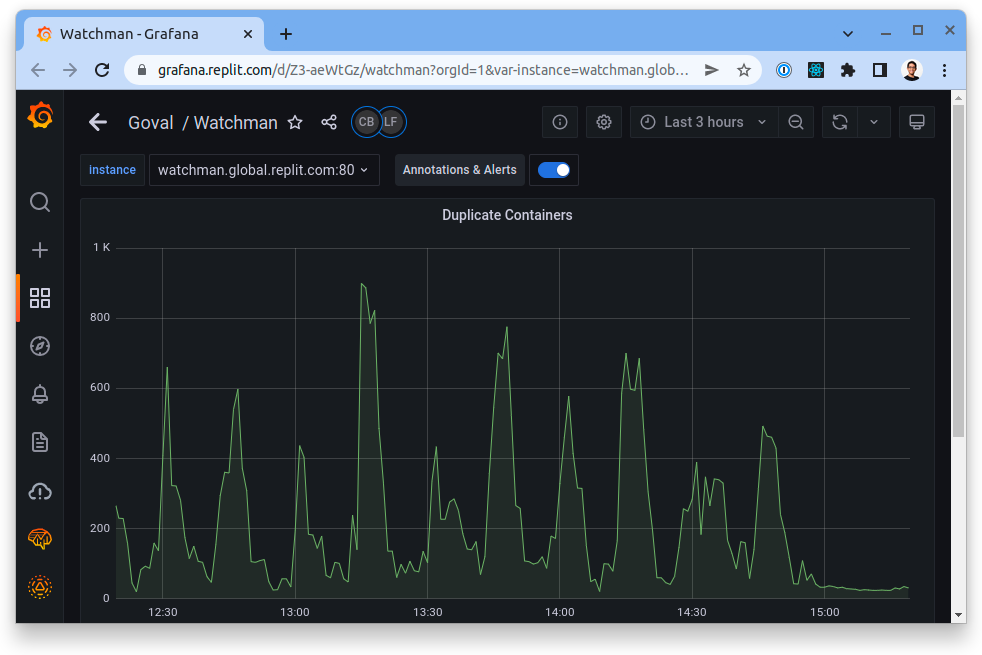
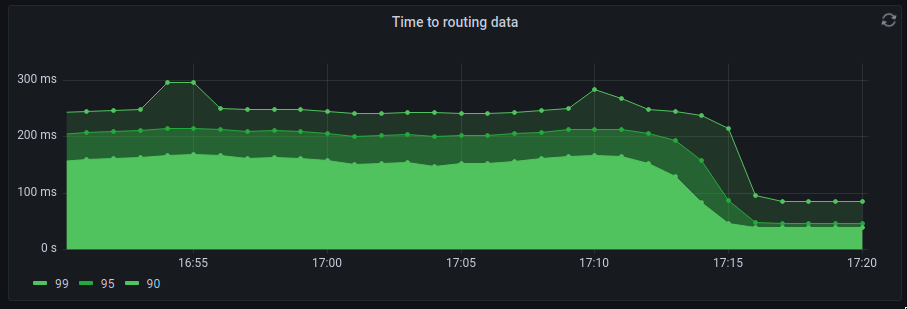
When it became time to make the switch, we decided to do so on an API-by-API basis to make the change more gradual. Over the course of several weeks, we started enabling a few APIs at a time that didn't have any inconsistencies between implementations. But then it came to a point where there was just one huge API left to migrate: the one where the .repl.co serving infrastructure grabbed the metadata needed to serve hosting requests for all the Repls. That was done with an immense amount of anticipation and all the Platform engineers obsessing over metrics. When the moment of truth came, it was an extremely boring event: nothing caught on fire or broke. But a few moments later, we had strong evidence that our efforts paid off: as a side-effect, we managed to reduce the 99th percentile latency of .repl.co hosting by 66%! And not only that, we simultaneously managed to completely eliminate all duplicate containers by having the source of truth for Repls and containers in our infrastructure in an ACID-compliant data store.
We like to play a game at the office called "try to guess when the change took effect". Let's see if you can guess!
The future
This is not the end of the journey for Worldwide Repls. In fact, this is just the very first big launch in a series of milestones!
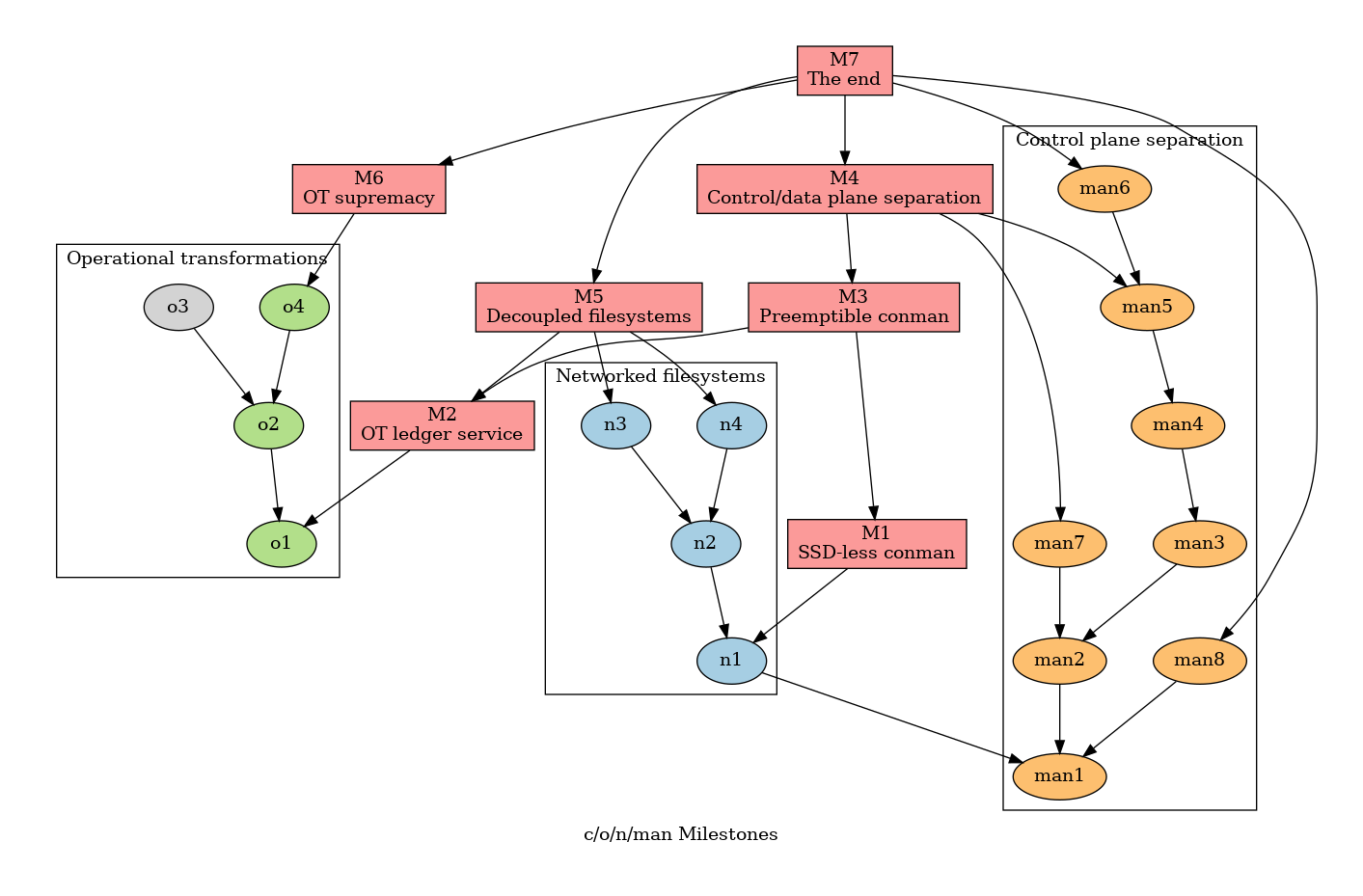
We are going to end with an almost completely rewritten system at the end, and at every stage of the way, we will be providing shiny improvements, either better performance or new features. Expect a lot more news about this, and we plan to have the next stage done by the fall of this year. Users in Asia should expect to see much faster Repls by then.
And remember that we are always hiring for remote engineers. So make sure to check that out. Expect another update soon!