
Having a solid foundation is critical for us to be able to fulfill our mission of making programming more accessible, more creative, and more fun. We did a great job of making the platform more stable during last year, but every now and then we would still run into unforeseen problems that cascaded into other parts of the platform, producing a bad experience for everyone. So back in October (just a few weeks after I joined the team) when we had 2 load-related site-wide outages within a week, we knew it was time to do a major overhaul of how our infrastructure handles traffic. And now today, we're announcing that as a side effect of that infrastructure change, Hacker repls now run in newer, more powerful machines, which means that we'll have more room to grow and experiment with more benefits for Hackers (and you might find that things feel a little bit snappier lately). This is the first of a three-part series of blogposts on how we rebuilt our infrastructure over the course of ~5 months.
Introducing a new failure domain
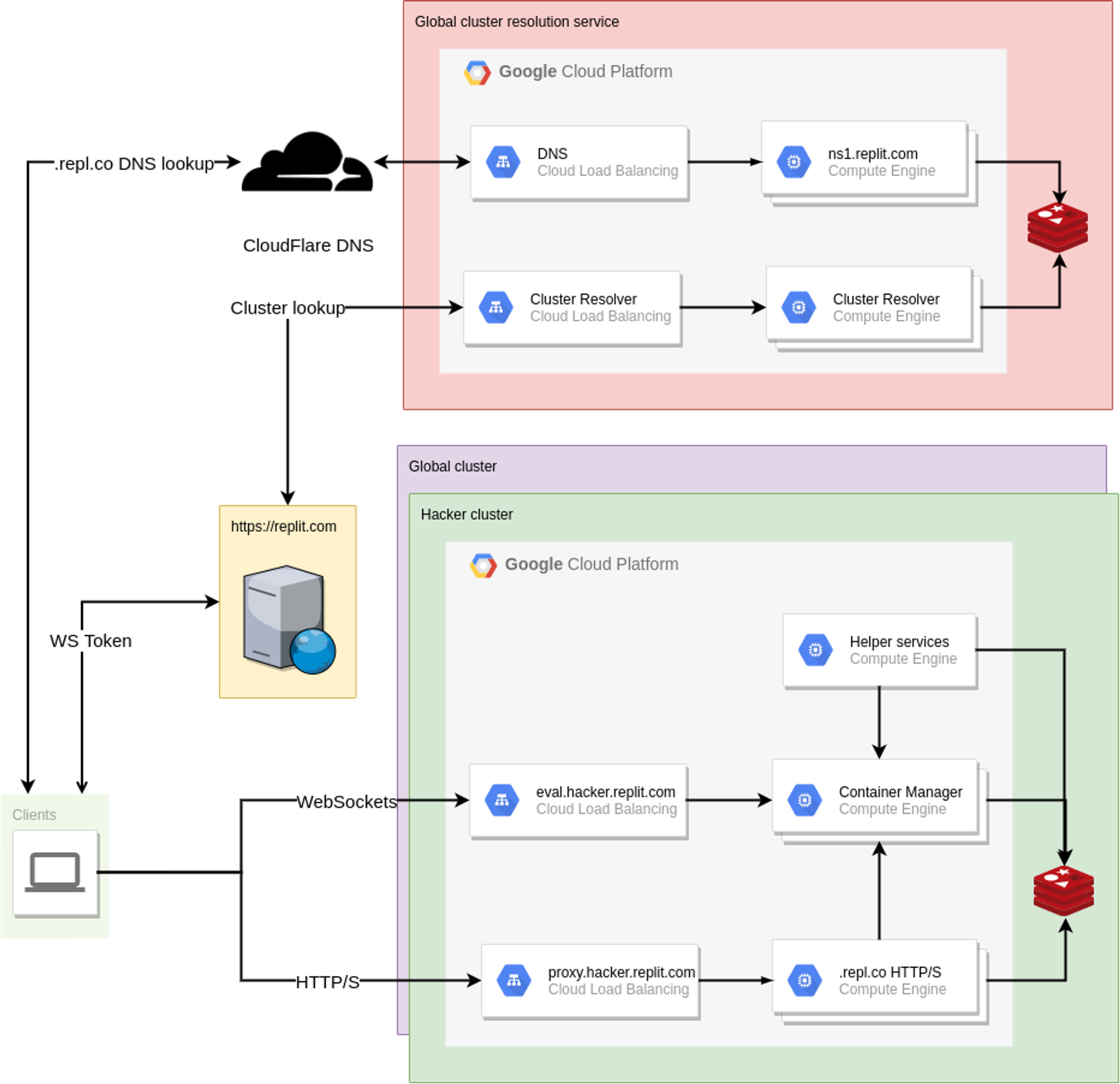
The original goal of this endeavor was simple, in theory: split the Replit infrastructure into multiple failure domains, so that when (not if) the next incident occurs, it only affects a subset of the users instead of all of them. There are multiple strategies to do so, and we chose to move Hackers to their own failure domain. But what does this split entail? Prior to this change, our backend infrastructure was relatively simple: a Google Compute Managed Instance Group of VMs that run containers, and another one that serves HTTP traffic on .repl.co domains.
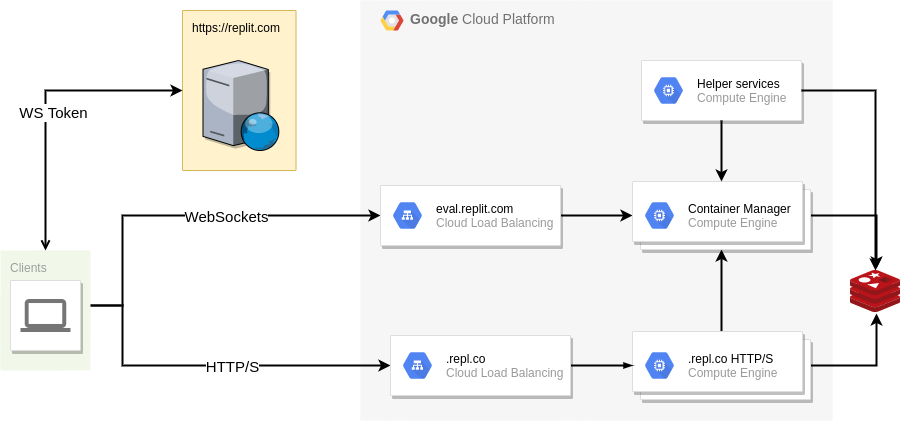
So in theory if we take the right-hand side of the diagram and make multiple copies of it, treating each one as a completely independent cluster, we solve the problem. Mission accomplished, right? Not quite: clients now need to know where to make their requests to, since they will now need to hit different hostnames depending on which cluster their repls are (since they are now completely independent after all). Clients that wanted to connect to their repl through the workspace were already required to contact the replit.com web server to get an auth token for the WebSocket connection anyways, so it would make sense for the web server to be the source of truth about the repl->cluster mapping. But what about hosting? All repls get a .repl.co domain, and users can CNAME them to be able to get to their app. At this point, the problem started looking very DNS-shaped, and that's kind of what we ended up doing: an external cluster resolution service, that can be used by both the Replit.com web server and individual clients trying to access their apps!
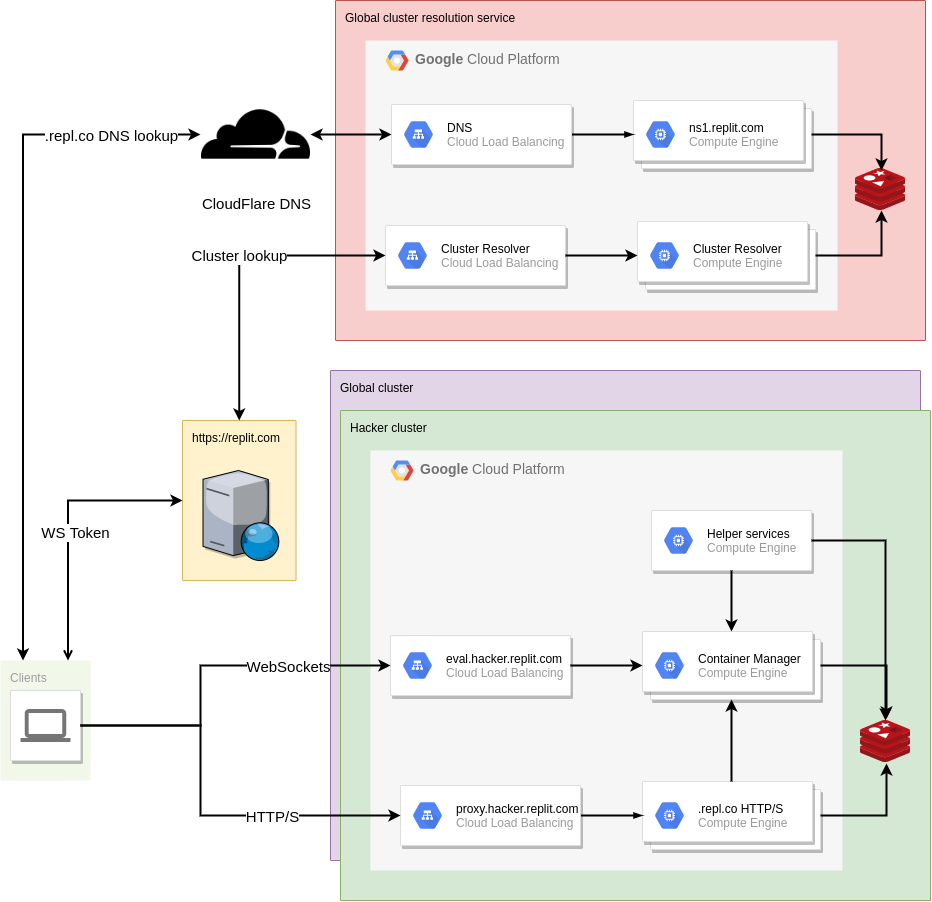
Given that everybody needed to make a DNS query to get the address of their .repl.co domains, exposing an external DNS server on the cluster resolution service made sense, which also made it such that there is no additional latency involved in this resolution!
With all the building blocks in place, there was one final thing that needed addressing: Eventual consistency. Distributed systems that are resilient, as well as those that have any amount of caching in place, benefit from being able to tolerate slightly stale information gracefully, with the knowledge that eventually the whole system will converge into a stable state. In this case, it is possible for one user to be transferred between clusters: since Hackers are located in a separate cluster, if the users' subscription status changes, they need to be relocated. DNS results can be cached for prolonged periods of time, which means that we need to be able to handle the case where a user tries to access their old cluster for that period of time. For that case, we use another tool from the distributed systems toolbox: Tombstones. When a user is moved from one cluster to another, a Tombstone is created in their original cluster, pointing at the destination cluster. Any attempts to contact any of their repls in the original cluster will then be responded by proxying the connection transparently to the new cluster during the TTL of the DNS record. And with that, the solution is now complete!
One of Replit's internal mantras is to ship things incrementally, even though we didn't transfer Hackers to their new cluster until fairly recently, all the infrastructure was in place beforehand. In order to test things out, during another load-related incident we decided to give this idea a try and move one user that had an extremely popular repl to the new cluster to test whether the goal of this project was achieved. Even though we knew there were rough edges, and the user transfer process was not widely tested before, we took a chance and used it. To our surprise, things worked better than we expected, and the incident was mitigated before it became a lot worse. Over the next weeks, the new cluster became one more way for us to move load around in times of emergency, which was a nice side-effect.
You might also remember that we blogged about our new global deployments: this was also one intermediate step of this project that we were able to launch early.
What this means for Hackers
Now that we are able to provision separate infrastructure for each cluster, the first thing that came to mind was to experiment with provisioning slightly different hardware in each cluster. To start, we are trying out how responsive repls are if they are running on machines that have a bit more headspace in terms of CPU and memory, since our theory is that there will be less contention over scheduling. We have a few more experiments planned to make the Hacker experience better, and we're going to make an announcement about this very soon.
What's next?
As I mentioned in the beginning of the article, this is part of a series of blogposts. In the next installment, Connor Brewster will go into more detail about our brand new DNS server. To wrap things up, Zach Anderson will describe some of the big deployment changes that we needed to do to achieve all this.
Happy repling!


{kind=link}