Programming languages with Garbage Collectors are fantastic! You no longer need to keep track of every single piece of memory that your program needs to run and manually dispose of them. This also means that your programs are now immune to bugs like double-free (accidentally freeing a resource more than once, leading to crashes or security vulnerabilities) and most memory leaks (accidentally not freeing a resource, leading to crashes by running out of memory). But it is still possible to have a memory leak. Consider this TypeScript snippet:
const globalCache: Record<number, number> = {};
/**
* Compute the n-th number in https://en.wikipedia.org/wiki/Fibonacci_sequence
*/
function fibonacci(n: number) -> number {
if (n <= 0) return 0;
if (n === 1) return 1;
if (!(n in globalCache)) {
globalCache[n] = fibonacci(n - 1) + fibonacci(n - 2);
}
return globalCache[n];
}The global cache makes fibonacci fast, but it relies on a global cache that has no way of being cleared, so it will always accrue memory when it is called with larger and larger numbers. Slowly but surely.
At some point during the development of Replit Agent, one of our engineers spotted the following graph in our dashboard:
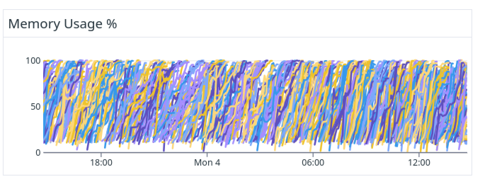
We had strong evidence that the agent processes were running out of memory roughly once an hour, and that likely means a memory leak. Since we were constantly serializing each agent process’ state to its Repl, we were able to recover without losing any data, but that meant that we had to re-run several LLM calls, and those tend to add up. This also implies that users would sometimes see some spurious slowdowns, so that was suboptimal too.
Normally we would have set up continuous profiling like we do for every single other load-bearing service at Replit, but this particular process is written in asyncio-flavored-Python, and the continuous profilers we tried earlier had introduced measurable performance or stability regressions, so we were relying on metrics only.
With that not being an option, the next thing that we did was to enable tracemalloc, which tracks blocks of memory allocated by Python. This means that it keeps a record of every single object, list, string, etc. that has been allocated, and it also notes when it’s freed, letting you know the code location of these allocations / frees.
tracemalloc is very convenient, since it is part of the standard library. Unfortunately, tracking all memory allocations in memory incurs some performance and more memory overhead, so instead we opted for something less intrusive: memray. Memray is an out-of-process memory profiler for Python that we can attach for a while to a process, inspect its memory usage, and then detach from it, as if nothing happened. A few advantages that memray provides over tracemalloc are that memray can also track native allocations (those made in native Python extensions like the ones made in numpy, orjson, or parts of pydantic), and it has a fantastic TUI that lets you see the allocations being done while the process is running. Agent runs typically last a few minutes at a time, which means that anything that is not freed within a few minutes has a high likelihood of being a real leak! After resetting the Python’s GC thresholds to the default (so that the GC ran very often), within a few minutes, the live mode had already shown several hundred MiB worth of allocated objects that had not been freed, like you can see in memray’s documentation:
So now you know you have a memory leak
It was fantastic that we could see what the leaked objects were within minutes. But that was just part of the puzzle: why were these objects leaked? For most programs, once you see what objects are allocated and never freed, that reduces the search space significantly, and you can fix the leak pretty quickly after that. Unfortunately, we couldn’t find the reason for the leak quckly: we seemingly weren’t saving these objects in a global variable. At least not intentionally. So what were we going to do about it?
Enter the gc module: in addition to having some functions to trigger the garbage collector, it had two extremely useful functions: gc.get_objects(), which returns the list of every single object that the collector knows about, and gc.get_referrers(), which returns the list of all objects that are referred to by any objects. With these two functions, we are now able to have a full visualization of the whole heap. This means that in addition to knowing what is being leaked, we can also know what is referring to those objects and finally fix the leak!
Since a few of us are Xooglers, our first inclination was to make this a zPage, which are endpoints in a built-in debug server (that is not open to the internet) that we can open from a browser (e.g. http://localhost:42424/heapz). This particular analysis was fast enough that it wasn’t going to negatively impact the asyncio event loop and cause trouble for any Agent run. But then we realized that a) we couldn’t find the leak while running in development, and b) iterating on this was going to be painful, since every tweak would require a full deployment. So it was time to do the next magic trick: how was memray being able to inspect a running process to begin with?
Non-intrusive heap inspection
Memray internally uses gdb, the GNU debugger, which can set breakpoints on a running program, pause its execution, resume it, inspect the source code and all the variables, and even call functions in the program! So all we needed to do is gently modify the code that it injects to do our heap analysis into the program and be done with it. Instead of reinventing the wheel, we first tried open source alternatives. https://github.com/robusta-dev/debug-toolkit was the first thing we tried (it uses the exact same gdb trick that memray uses when saving a report to disk for future analysis), but we were greeted with a suspicious error when trying to call malloc(3), which gdb uses internally to copy the injected code to the target process. Something in our container image build process was doing something funky and messing up with gdb’s ability to find the location of the malloc function in glibc, so we weren’t able to use that debug-toolkit as-is (and just to confirm our suspicion, memray was also not able to dump a report, so it was something that affected anything that relied on gdb). Our engineers started looking into why that was the case, but in the meantime, we wanted to get ourselves unblocked by whatever means: It’s time for hackery.
Using gdb directly was out of the question because it tried to use malloc(). But what if we were to do the same steps that gdb did but without calling that glibc function? Enter the underlying Linux system call gdb uses to debug a running process: ptrace(2). With ptrace(), it is possible to observe and control the execution of a running program. Typically this is done through the PTRACE_ATTACH request and once we’re done with it, the PTRACE_DETACH request will let the program run as it was before. While we are attached, we can inspect the CPU registers using PTRACE_GETREGS, let the process run a single instruction with PTRACE_SINGLESTEP, and continue its execution with PTRACE_CONT (this is what the “observe and control the execution” meant before). But how did gdb call arbitrary functions? Julia Evans did a small investigation before and outlined that process as follows:
- Stop the process
- Create a new stack frame (far away from the actual stack)
- Save all the registers
- Set the registers to the arguments you want to call your function with
- Set the stack pointer to the new stack frame
- Put a trap instruction somewhere in memory
- Set the return address to that trap instruction
- Set the instruction pointer register to the address of the function you want to call
- Start the process again!
debug-toolkit uses a snippet of GDB commands copied from Microsoft’s debugpy:
call ((int (*)())PyGILState_Ensure)()
call ((int (*)(const char *))PyRun_SimpleString)("{python_code}")
call ((void (*) (int) )PyGILState_Release)($1)The main problem is that one of the functions we wanted to call (PyRun_SimpleString) takes a string pointer: this is why gdb was trying to call malloc() to begin with, and we couldn't use that! And that also involves storing the return value of the first call and pass it as an argument to the third function, so the amount of work needed to roll this out by hand was rapidly increasing. Still, we needed to allocate some memory somehow, and we needed to call some functions: what if we simplified things to write to memory once and call a single function? And what if we were to be able to write a tiny function that we can call instead of stitching together multiple functions that are already there in the process? In other words, what if we could compile this little C function into an executable snippetThis style of programming is normally used in offensive security to try to exploit vulnerabilities. It’s commonly known as shellcode.?
typedef int (*PyGILState_Ensure)();
typedef void (*PyGILState_Release)(int);
typedef int (*PyRun_SimpleFile)(void *, const char *);
__attribute__((noreturn))
void run_python(PyGILState_Ensure PyGILState_Ensure, PyGILState_Release PyGILState_Release, PyRun_SimpleFile PyRun_SimpleFile) {
static const char payload_code[] = "This code will be added at runtime";
int gil = PyGILState_Ensure();
int result = PyRun_SimpleFile(f, (const char *)path);
PyGILState_Release(gil);
// int3 causes the process to emit a SIGSTOP so that ptrace() gets notified.
// Copying `result` to the "a" register a.k.a. rax so that we have an
// easy time extracting it as-if it were the return value.
__asm__ volatile inline (
"int3\\n"
:
: "a"(result)
);
}If we compile this with clang -Oz, we get a pretty concise piece of code that is entirely self-contained, and only relies on relative jumps, perfect for our purposes! This function only has three arguments that can fit on registers (they’re all pointers to functions), and the x64-64 calling convention in System V ABI determines that we can call this function relying only on passing these arguments in registers, which simplifies things a little bit for us. So all that’s left is for us to solve the original problem, with a twist: allocating memory in a way that is writable and executable.
For that, we enlist the help of two more system calls: mmap(2) (allocates memory directly from the kernel) and process_vm_writev(2) (transfer data to the target process). But how do we even invoke a syscall in another process? Normally you would use ptrace’s PTRACE_POKETEXT to overwrite whatever is being executed with a x86_64 SYSCALL opcode (and restore what was there earlier after you’re done), but that felt a bit too dangerous. Fortunately the SYSCALL opcode is fairly common in glibc, so all we need to do is scan a few functions until we find one such opcode. Invoking most syscall only requires setting registers before executing that opcode, so we can change the instruction pointer (a.k.a. RIP in x86-64) together with the rest of the arguments in one PTRACE_SETREGS and we have successfully executed a syscall in the target process!
Now we have everything we need to achieve our original objective, which looks a bit different from Julia’s list:
- Stop the process (using
ptrace(PTRACE_ATTACH, pid, ...)) - Save all the registers before doing anything (we’ll need to restore them at the end).
- Using an ELF library and reading
/proc/${pid}/maps, find the absolute addresses of all the functions we need for our shellcode (PyGILState_Ensure,PyGILState_Release, andPyRun_SimpleFile), plus one instance of theSYSCALLopcode (we used thesyscallandopenatfunctions since at least one of them was in the wrong spot in our process). - Allocate memory to hold the shellcode (invoking the
mmap(pid, 0, 4096, PROT_READ | PROT_WRITE | PROT_EXEC, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0)syscall in the target process). - Write the shellcode plus the Python code to be executed (using
process_vm_writevsyscall in the local process). - “Allocate” the stack by pretending to run the function (this was mostly moving the stack pointer a.k.a.
RSP128 bytes to avoid the red zone and aligning it to an 8-byte boundary and then pushingRIPinto the newly-allocated stack frame) - Set the registers to the arguments you want to call your function with (the addresses of all the functions we need).
- Continue the process until the SIGSTOP signal is raised (in other words, reaching the
int3opcode in the shellcode). - Clean everything up (call
munmapto release the memory allocated and restore the registers to their original values).
And that was the hard part. With this we could iterate quickly on the little snippet of Python code to dump the heap and all referrers, on a production machine that was afflicted! This ended up being a variation of the following code:
def __payload_entrypoint(output_path: str) -> None:
import asyncio
import inspect
import logging
import gc
import sys
logging.warning("XXX: dump_heap: writing report to %r", output_path)
logging.warning("XXX: dump_heap: collecting gc")
gc.collect()
seen: set[int] = set()
seentypes: set[type] = set()
ignored_addrs = {id(seen), id(seentypes)}
ignored_addrs.add(id(ignored_addrs))
logging.warning("XXX: dump_heap: collected gc")
try:
with open(output_path, "w") as output_file:
queue: list[tuple[Any, int, bool]] = [
(o, id(o), True) for o in gc.get_objects()
]
x = 0
totalsize = 0
while queue:
if x % 100_000 == 0:
logging.warning(
"XXX: dump_heap: %d / %d (%5.2f MiB)",
x,
len(queue),
totalsize / 1024.0 / 1024.0,
)
x += 1
obj, addr, root = queue.pop()
if addr in ignored_addrs:
# We don't want to track the objects we own.
continue
if addr in seen:
continue
seen.add(addr)
objtype = type(obj)
objtype_addr = id(objtype)
if objtype not in seentypes:
output_file.write(
f"TYPENAME type_addr={objtype_addr:x} name={objtype.__module__}.{objtype.__name__}\\n",
)
seentypes.add(objtype)
size = sys.getsizeof(obj, 0)
totalsize += size
output_file.write(
f"OBJECT addr={addr:x} type_addr={objtype_addr:x} size={size:x}\\n",
)
referents = gc.get_referents((obj,))
for child_obj in referents:
child_addr = id(child_obj)
output_file.write(
f"REFERENT addr={addr:x} referent_addr={child_addr:x}\\n",
)
queue.append((child_obj, child_addr, False))
del referents
output_file.write("DONE\\n")
logging.warning(
"XXX: dump_heap: %d / %d (%5.2f MiB)",
x,
len(queue),
totalsize / 1024.0 / 1024.0,
)
del queue
except:
logging.exception("XXX: dump_heap: failed to collect")
raise
finally:
del seen
del seentypes
del ignored_addrs
import gc
import threading
OUTPUT_PATH = "/tmp/result.bin" # the result of the dump
DONE_PATH = "/tmp/done.txt" # write to this file to signal doneness
def __wrapper() -> None:
exc: BaseException | None = None
try:
__payload_entrypoint(OUTPUT_PATH)
except BaseException as e:
exc = e
finally:
try:
# Make sure that everything can be gc'd.
del globals()["__payload_entrypoint"]
except: # noqa: E722
pass
gc.collect()
with open(DONE_PATH, "w") as done_file:
if exc is None:
done_file.write("SUCCESS")
else:
done_file.write(f"ERROR: {exc}")
# Run this in a separate thread to minimize disruption of whatever code
# Python was executing when we attached. The Global Interpreter Lock
# will still be held in the other thread, though.
thread = threading.Thread(target=__wrapper, daemon=True)
thread.start()This code:
- Creates a new thread (the code in the thread is still going to hold the GIL, but the main thread will be able to run without being blocked).
- Run a GC cycle. This is important because the GC only tracks objects it has seen in at least one GC run.
- Open a file that will be written using just standard library functions to avoid having to add any extra dependencies to the program.
- Gather every object the GC knows about.
- For every object,
- Dump its type name if we hadn't visited it before
- Dump its address, type, and size
- Dump all of its referents.
- Add all of its referents to the queue
The whole code for this can be found at https://github.com/lhchavez/dump-heap (not an official Replit-supported product). It also contains a precompiled statically-linked binary that you can just curl in a running Docker container, and way to visualize it through text and SVG
Fixing the leak
After that humongous detour, now that we have the heap data, we can see what objects are holding onto stuff. Here is one trace that looked at the biggest leaked object and what was transitively holding onto it (the first line is the leaked object itself, and every subsequent line is an object that holds a reference to it, slightly redacted.):
INFO:root: ==== LEAKED OBJECT ====
INFO:root: size address type
INFO:root: 1256271 000059f94fccdfb0 builtins.str
INFO:root: ==== REFERENT CHAIN ====
INFO:root: size address type
INFO:root: 184 00007f8e82614e80 builtins.dict
INFO:root: 72 00007f8e825ab700 ...models.UrlImage
INFO:root: 184 00007f8e82616bc0 builtins.dict
INFO:root: 72 00007f8e825ab750 ...models.ImageContent
INFO:root: 80 00007f8e827c6d80 builtins.list
INFO:root: 184 00007f8e82617340 builtins.dict
INFO:root: 72 00007f8e825ab7f0 ...models.PromptChatMessage
INFO:root: 272 00007f8e827c6140 builtins.list
INFO:root: 184 00007f8e8259f580 builtins.dict
INFO:root: 72 00007f8e8256b020 ...models.ChatCompletionInput
INFO:root: 184 00007f8e825a1c80 builtins.dict
INFO:root: 832 00007f8e8258f100 builtins.dict
INFO:root: 56 00007f8e825a1710 langsmith.run_trees.RunTree
INFO:root: 88 00007f8e825667c0 builtins.list
INFO:root: 832 00007f8e825a1640 builtins.dict
INFO:root: 56 00007f8e82564ed0 langsmith.run_trees.RunTree
INFO:root: 88 00007f8e82564e00 builtins.list
INFO:root: 832 00007f8e82564f80 builtins.dict
INFO:root: 56 00007f8e827c5e50 langsmith.run_trees.RunTree
INFO:root: 120 00007f8e83164f40 builtins.list
INFO:root: 832 00007f8e8257b700 builtins.dict
INFO:root: 56 00007f8e82665fd0 langsmith.run_trees.RunTree
INFO:root: 80 00007f8e8269ea20 builtins.hamt_bitmap_node
INFO:root: 144 00007f8e8371f370 builtins.hamt_bitmap_node
INFO:root: 56 00007f8e82566000 builtins.hamt
INFO:root: 64 00007f8e827c5640 _contextvars.Context
INFO:root: 192 00007f8ea89e7640 _asyncio.Task
INFO:root: 48 00007f8e82650a70 ...OneOfOurAsyncGeneratorClasses
INFO:root: 64 00007f8e8258ff40 builtins.method
INFO:root: 80 00007f8e8256ac00 weakref._Infoall of the langsmith and models classes were innocuous: they were simple containers. But the OneOfOurClasses that held onto a task and was referenced by a weak reference looked super suspicious. The root cause ended up being a confluence of two surprising behaviors of Python async internals:
asyncio.Taskobjects need to be referenced by something, otherwise they will be garbage collected, potentially mid-execution. The documentation suggests a pattern like:
background_tasks = set() # Editor's note: uh-oh. Remember this from
# the first snippet?
for i in range(10):
task = asyncio.create_task(some_coro(param=i))
# Add task to the set. This creates a strong reference.
background_tasks.add(task)
# To prevent keeping references to finished tasks forever,
# make each task remove its own reference from the set after# completion:
task.add_done_callback(background_tasks.discard)- If an async generator is interrupted, it’s not guaranteed that its cleanup will be called in the same context and instead will be done by the garbage collector. Normally, this spells trouble for
contextvars, which rely on being called in the same context, but in our case, it meant that any cleanup done in an async generator will only be performed by the garbage collector, after it is finalized.
These two things, plus the particular way OneOfOurAsyncGeneratorClasses was written, meant that if any of its callers or their transitive callers did not fully drain the generator (because they breaked out of it, or an exception was raised), the cleanup never happened, and it artificially kept everything it could reach alive. Forever! This, by the way, was the reason this never showed up in development: this only happened when there were exceptions, and it relied on real user interaction that failed with very low probability.
After fixing OneOfOurAsyncGeneratorClasses to make it super simple (no more need to have weak references, or finalizers, or cleanup), and reliably clean up after every single async generator in the codebase (you can use contextlib.aclosing for that, and make sure this is added to your favorite linter), memory of the pods was finally under control!
We have now added a lot of extra observability to make this process easier in the future. We also added an alert that lets us know if there are any more OOMs in production so that we can easily roll back to safety and then address the regression.
We have one more cool use of the gc package that we’re cooking. Stay tuned for that blogpost!
If you enjoyed this riveting saga, remember that we’re hiring!