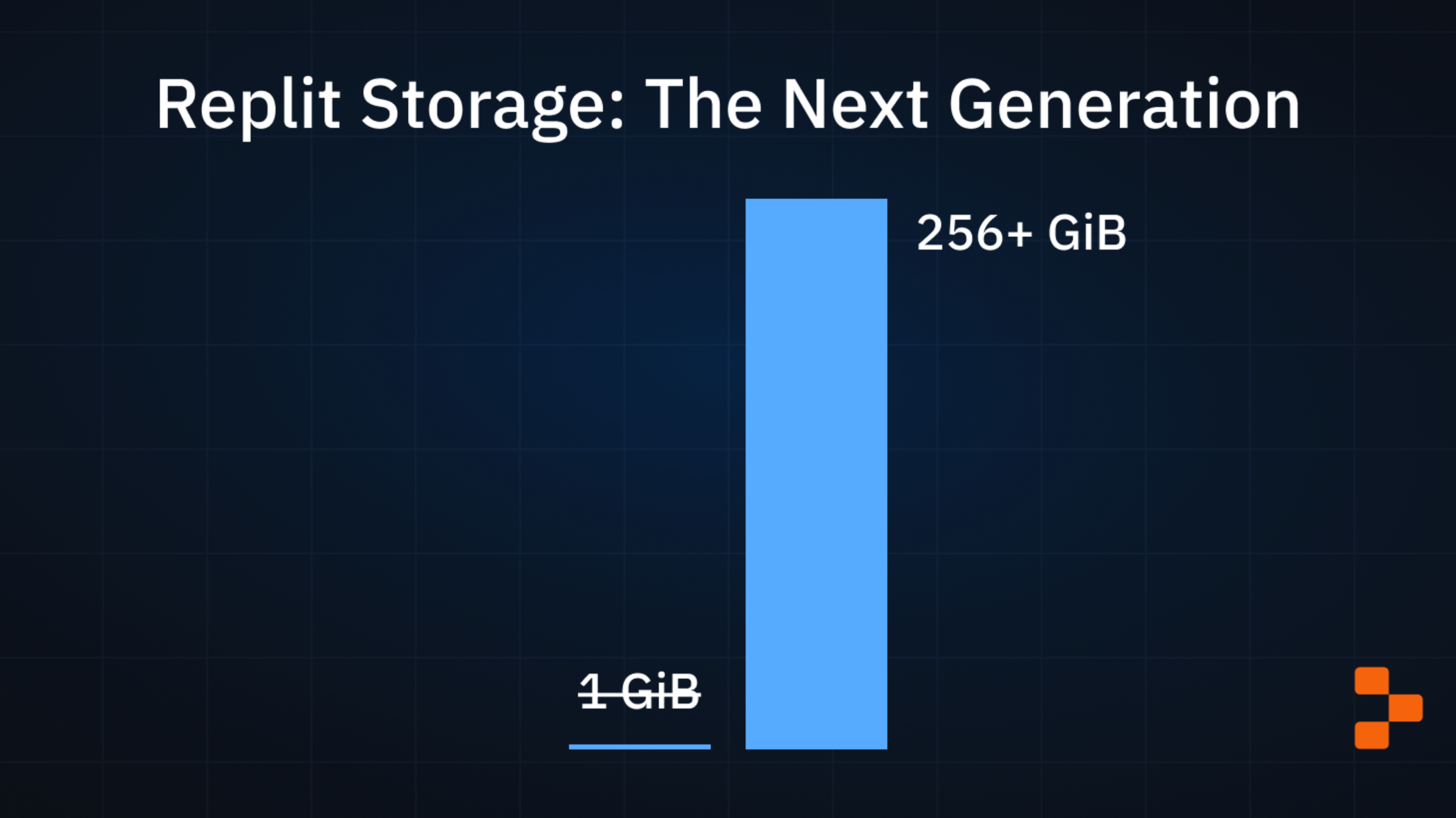


Repls today allow 256+ GiB of storage space, up from a historical 1GiB limit. This post is about the infrastructure that enabled that change.
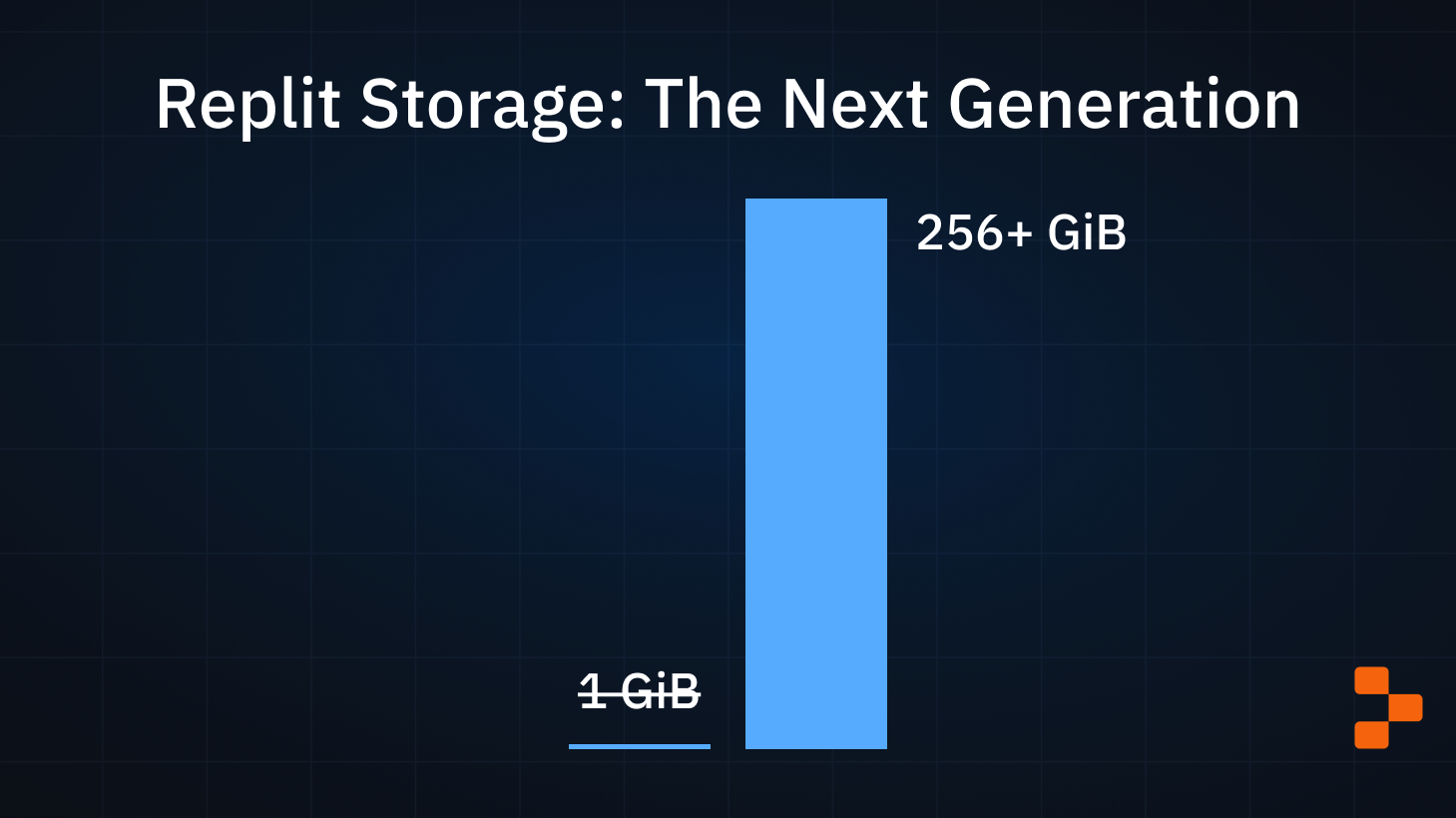
Historically Replit limited files in each Repl to 1 GiB of storage space. The 1 GiB limit was enough for small projects, but with the advent of AI model development and with some projects needing gigabytes worth of dependencies to be installed, 1 GiB is not enough. We announced on Developer Day that we were rolling out the infrastructure to unlock much larger Repls, and this is the first part of that. Read on to see why that limit existed in the first place, what changed, and how we pulled it off.
How Repls Previously Operated
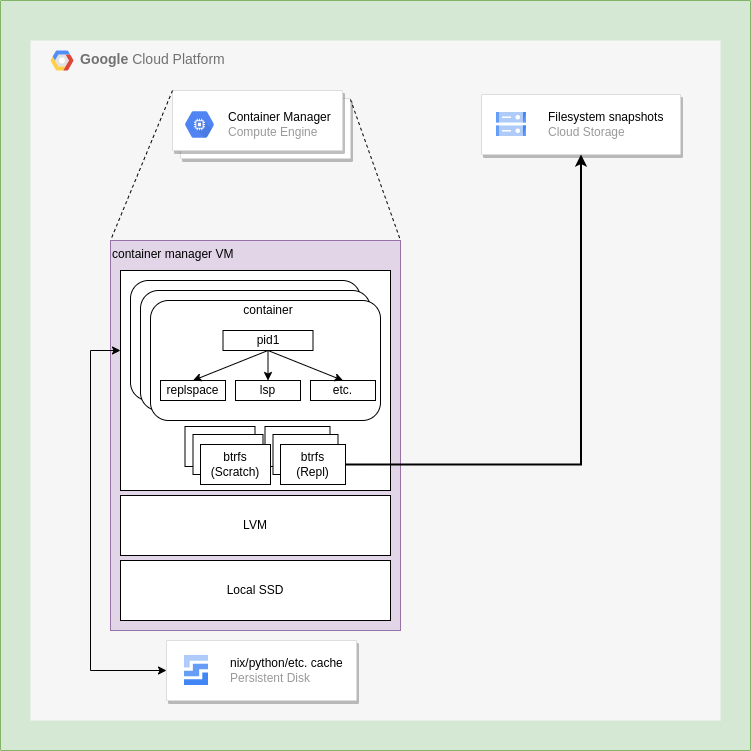
All Repls use btrfs as their filesystem of choice. Back in 2018 when this decision was made, btrfs was already a very stable filesystem (and even some Linux distributions, like Fedora, later adopted it by default). Aside from its stability / performance considerations, the two features we really liked about btrfs were that it supported setting quotas (to enforce the 1 GiB per-Repl limit) and that it supported copy-on-write snapshots as the building blocks for storage.
That takes care of the filesystem aspect, but how were the filesystems provisioned? Since we run several Repls in each actual machine, the provisioning of block devices was done through LVM thin pools, which allows having a fixed-size physical block device and creates an arbitrary number of virtual block devices, as long as the total used size of all the block devices doesn’t exceed the capacity of the physical block device.
These two building blocks came together to provision Repls' filesystems: every time a new Repl started, we asked the LVM thin pool for two 2 GiB devices, format them both as btrfs, set a 1 GiB quota on one, and then do very complicated mounts with overlayfs: The device with 1 GiB quota becomes the Repls' filesystem (mounted at /home/runner/${REPL_SLUG}) and the other one (known as the "scratch" disk) becomes the upper dir for every other directory in the system that is writable (like /home/runner, /nix, /tmp, etc.). Once the Repl's filesystem is mounted, we streamed a serialized version of the last snapshot of the filesystem, and then the Repl was ready to go!
All this process was slower and more brittle the larger the Repl was. And that was the reason why Repls had been historically capped to 1 GiB: anything else was way too much for this system to handle, since folks would be waiting several minutes for the filesystem to be deserialized, even with clever compression techniques and pooling thousands of ready-to-go pre-formatted virtual LVM devices. That was a terrible experience for Repls larger than a certain size, especially if there was any problem with the Repl, since it would need several minutes to recover (or worse: several minutes to crashloop). In fact, we tried using this technique to develop the first proof-of-concept for Replit on Replit several months ago, and while it was a neat experiment, it was pretty much unusable due to the slow boot times. Side note, this was also extremely expensive: every time any file in a Repl was changed, we needed to do a full snapshot and save the full serialized version to stable storage. We ran a profile of the system, and we were burning around 50% of the CPU just on this process.
I can't believe it's not btr(fs snapshots)
We knew we had to move away from persisting disks as snapshots. Allowing Repls to grow to unbounded sizes would increase boot time as well. Instead of persisting entire Repls all at once we needed a system that would allow a Repl to access the data it needed on demand, without loading the entire contents of the Repl at boot. Our first prototype of expandable storage gave each Repl its own NFS directory. Network File System is a network-first shared filesystem that was designed to solve the problem of sharing a filesystem between many computers across a network. While NFS solved our problem in theory, it quickly developed some cracks.
Deciding to move to a network file system was only half the battle. We considered whether migrating everything to a managed NFS service could serve this need, but nothing we could find would be able to scale to the size and performance we needed. We would have to build something bespoke. Because NFS is a filesystem, it is a complex protocol. Permissions, metadata, directory structure, ensuring consistency, and every other filesystem concern has to be handled at the protocol layer. Implementing our own NFS server that could store files to permanent storage (we're using Google Cloud Storage or GCS for that) could be very error prone, and once we built it we would need to write to a GCS file every time anyone touched a file in a repl, which would be cost prohibitive and high latency. Between the amount of effort that building a safe NFS service would take, and the risk that making such a service fast enough for the experience in a repl to feel local, we decided we needed to think simpler.
The biggest challenge in a network filesystem is ensuring consistency across many clients. Since Repls are only running in one place at a time, that isn't an issue for us. If you remove the multi-writer requirement from a network file system, then it's really no different from a local filesystem. With that in mind we considered leaving the filesystem on the machine running the Repl, and instead moving the disk itself to another machine.
There are many protocols to serve a block device, something that the kernel sees as a raw disk, over the network: iSCSI, AoE, various flavors of fiber channel, NBD. All of them allow a remote machine to provide a disk that can be accessed just like any other disk attached to the machine. That would enable us to continue using btrfs as the filesystem for a repl, and not pay any of the performance overhead of moving the entire filesystem to the network, while still allowing us to store the bytes of a repl off the machine. And it simplifies the persistence problem from storing thousands of separate files with their own metadata and permissions to storing a big chunk of bytes.
While there are many existing servers for serving disks over the network, most are tailored to the needs of SANs, where exports are configured statically and disks are served to a fixed number of long-lived clients. In order to store to GCS, we needed to build something ourselves. That service we called margarine[1], and since it needed to be blazing fast, we wrote it in Rust.
How does it work
When you boot up a Repl, the machine running it sends a connection request to one of our margarine servers, chosen with our own loadbalancer. The server validates the request and establishes an NBD session with the Repl. That is all that needs to happen before you boot your Repl, meaning Repls can boot instantly now, regardless of how big they are.
Of course your Repl is probably going to need to access some files once it boots up. It will try to read things from btrfs, which will start sending requests to read sectors of the NBD disk to the margarine server. Margarine slices up the entire virtual size of the disk into 16MiB blocks and determines which block the requested sectors fall into, downloading that entire block from GCS and writing it to a local scratch disk. The resulting 16MiB from GCS is then sliced up again into 512KiB blocks and copied into memory. Any requests can then be served directly from memory. By transferring 16MiB back and forth from GCS all at once we can take advantage of the fact that file systems try to group relevant data on disk, this allows us to minimize the amount of time we spend page faulting to a high layer of the cache and keep things moving quickly. Many of our templates are small enough to only require downloading one or two files from GCS in order to populate their entire filesystems.
As you access data in your Repl, margarine can add and remove things from its cache and move things from disk to memory so that what you need is always fresh, while things that you aren't using anymore can be shuffled back out to GCS until they're needed. The result is a virtual disk that is bounded only by the maximum size of a btrfs filesystem (16EiB ought to be enough for anybody).
Transaction-safety
In our old implementation, every time there was an explicit readonly snapshot when we wanted to serialize the filesystem, the filesystem had good guarantees of being in a very consistent state. Now we are always sending all filesystem writes over the network, and anything that goes over the network can be disconnected for all sorts of reasons. This meant that Repls would now be a lot more susceptible to random data corruption. This was enough of a worry that we added chaos testing tools that injected network failures at random points during the connection by dropping connections using tcpkill under multiple workloads and reconnecting, over and over. And we did end up getting corrupted btrfs filesystems within seconds :'(. Of course, the client can try its very best to avoid losing a connection, but the network is mostly out of our control, which meant that we needed to actively prevent this from happening. So we needed to figure out how to a) detect safe points to actually persist the filesystem contents to permanent storage and b) discard anything that was modified since the last safe point if the connection got dropped unexpectedly. All that was left was to understand how btrfs works in the kernel.
Btrfs is a copy-on-write filesystem based on btrees, which_ roughly _means that every time there's a change in the data in the system, it creates a copy of the data and all the btrees that reference it, writes all the updated data structures in another region of the device, and then it deletes the original copy when it's no longer needed. But if information is not updated in-place, how does one find the latest state of the system? There is just one exception to that rule: the super blocks. These are in-disk data structures that are located in fixed locations in the device, and have pointers to the "root btrees", which hold pointers to all other btrees that store data and metadata. This is an oversimplification of how btrfs works and lays the data on disk. If you want more information, Dxu wrote a very good series of blogposts that talk about btrfs internals. Ohad Rodeh also presented some of the concepts used by btrfs in B-trees, Shadowing, and Clones.
Keen observers might realize an important consequence of btrfs' design: the moment after all the super blocks are updated is when the filesystem is fully consistent. All the on-disk data structures are freshly written, and the pointers to these data structures are now updated in the super blocks. And since the super blocks are written to fixed locations, we can detect every time this happens. If we look at the kernel implementation of the point in time in which transactions are finalized, we arrive at write_all_supers. This function ultimately does a sequence of sending a flush request, writing the first super block with the Force Unit Access flag (FUA), and then writing the rest of the super blocks. This sequence is pretty easy to detect server-side due to the fixed offsets and sizes of the writes (4 kiB each), and we use it to know which are the safest points to fully persist the contents of the filesystem.
It turned out that completely ignoring the kernel's flush / FUA requests and detecting this sequence made our chaos tester completely happy: no more data corruption![2] This makes our implementation somewhat tightly coupled with the btrfs implementation, but it's the only filesystem we're going to support in the foreseeable future.
Global copy-on-write
While writing the transaction-safe functionality we needed to have a way to persist the contents of the filesystem atomically and asynchronously, because now we're persisting potentially hundreds of megabytes at the same time, and having the kernel wait for the filesystem to be fully flushed to persistent storage took way too much time. This now meant that if we happened to fork a Repl mid-transaction, we would end up with an inconsistent view of the filesystem, undoing all the work that we had done before! But if we took a step back, this sounded a lot like the same problem that btrfs is solving with their transactions. So what if we used the same solution: copy-on-write? It turns out that it worked very well! And as a bonus, it unlocked a few more things.
Every Repl has a small "manifest", which is a fancy word for a map of the used blocks that each Repl has. Each block has a UUID assigned to it when it is created, and also every time a block transitions from being clean (its contents exactly match what was persisted to permanent storage) to being dirty. When there is a btrfs commit, we create a copy of this map, update it with pointers to the new blocks, and persist the blocks with their associated UUID, plus the manifest. So as long as the manifest reads are atomic, we can guarantee that every time there is a fork, we are getting a consistent snapshot of the full filesystem. And now that we have copy-on-write for every Repl, we can do something cool: instant and cheaper forks. A fork of a Repl now only needs to copy the manifest, and all the blocks owned by the original Repl will be copy-on-write modified by the fork, which saves on storage. But now that we had forks, we also realized that we gained something we didn't expect: we can have the full filesystem history of a Repl! Saving every full snapshot of every Repl would quickly get out of control, so we ended up using Evan Wallace's excellent Logarithmically-Spaced Snapshots algorithm to have a rough upper bound on the storage that each Repl could use in total, plus being able to have multiple versions of the full filesystem for recovery purposes just in case something went terribly wrong, as well as being able to debug some very difficult-to-diagnose bugs that we've seen over the years.
Finally, the last side-effect of this move: read-only forks are still possible, and cheaper too. We use those every time a user visits a Repl owned by another user. With a little bit of work, we were also able to make this whole scheme geographically-aware so that users in India could fork Repls from the US and vice versa. So many benefits, there has to be a catch, right? Well, yes: Part of the copy-on-write process is that we need to delete blocks that are no longer being referenced. Now that we have multiple locations where data could be stored, it makes things a bit harder. As it turned out, a very simple tracing garbage collection process, where we scan all manifests to see what blocks they reference, the blocks that are present, and then take the symmetric difference to see what blocks are present but not referenced did the trick, with some additional constraints to accommodate for manifests that were created / modified since the scanning process started. Fully copy-on-write-enabled geographically-aware Repls!
What's next?
We have all the necessary infrastructure in place to start the rollout for all Repls to have larger filesystem sizes. Stay tuned for an upcoming blogpost where discuss some of the specifics around enlarging Repls! Expect some news in the next couple of weeks!
We're also in the process of upgrading our production kernels because there is one very shiny feature that is going to let us do much better detection of safe points and allow the editor to know what versions of the files have been persisted all the way to permanent storage.
Work at Replit
Are you interested in Linux and filesystems? What about networking and distributed systems? Come work with us to solve challenging problems and enable the next billion software creators online.
Footnotes
- Margarine: it's not btr(fs) snapshots, ha ha. We love puns. ↩
- Turns out that there was one more case when this happened: if there are creations / deletions of btrfs snapshots and the connection is dropped at just the right time, there are some orphans that are not completely cleaned up. We haven't yet identified how non-cleaned orphans end up corrupting the filesystem after multiple rounds of the chaos tester, but since we stopped needing to do btrfs snapshots altogether, we didn't pursue any further. Do reach out if you're interested in getting a repro scenario to file a bug report, though! ↩


{kind=link}