
 Fri, Sep 10, 2021
Fri, Sep 10, 2021Data Loss: a sad tale with a happy ending
Earlier this year, we discovered that we were losing data for some of our users. This manifested as either repls being completely empty after reloading, or some of the changes to files not being present after reloading. Obviously losing data is the worst we can do, so we had to fix this immediately. This blog post narrates the adventure of how we discovered this, how we fixed it, and the lessons we learned during the way. The discovery Throughout the year, we had had some worries about some theoretical cases in which users could lose data. We have had a few complaints from people that their code wasn't correctly saved, and since we weren't sure what caused them, we just tried to fix bugs here and there one at a time in an unstructured fashion. Around mid-July, we got an alarmingly large number of reports of people about their code not saving correctly in a short amount of time, ironically just after deploying one such fix. This meant two things: our intuition about folks losing data was correct, but the way we were fixing it was not! This led to the immediate discovery that there were months- or years-old bugs that were silently losing or corrupting data, and some of them turned out to be load-bearing bugs that couldn't be fixed in isolation (since fixing them triggered other kinds of data loss). This made us start a much larger project to have better guarantees and incrementally fix things without regressions. Homer Simpson doing a dramatic impression of this whole situation
 Wed, Sep 1, 2021
Wed, Sep 1, 2021Making Replit Faster for Everyone
Replit's mission is to make programming accessible and provide computer superpowers. To achieve that goal, repls need to be fast. To that end we've been working on a number of improvements in our infrastructure and code to unlock faster repls. We constantly analyze the speed of our clusters and identify areas of improvement. Here are a few examples. Editing Code Just Got Faster We split repls woken up by hosting (repl.co, custom domains) to different VMs than repls that you access in the workspace. This makes editing code and interacting with your repl in the workspace faster by ensuring your usage isn't competing with nearly as many other repls. For repls being actively edited in the workspace, we've seen an average 10-20% improvement in speed from this change. This applies across all subscription types including free users. More CPU For Your Repl
- Thu, Aug 5, 2021
Replit²
Replit has many use cases and features, but one that's less talked about is its ability to serve as a secure compute environment for specialized apps. What if you want to build some tool that will generate code, then execute it for your users? Or maybe you are building a specialized online IDE that injects code for users, then executes the bundle? With Replit, you can start building those kinds of applications quickly without having to focus on building a fast and secure backend. Build the frontend, we'll provide the compute power. That's a great promise, but it's not one that is fully documented. Well, now that is a thing of the past! Let's explore how Replit can serve as your compute backend by building a very basic Replit clone. UPDATE 2021-08-16: Please check the section on Security at the end of this post, more details were added and the post was clarified thanks to the help of @AmazingMech2418. Building a compute node A compute node is a single unit (usually a single server, VM, container, or application) of computing power than can execute work. In our case, a compute node will be a single Repl that can execute arbitrary code using an API. We'll be using the Koa.js framework and python in this post. Let's start by creating a new Nix repl. Why Nix in particular? Nix allows us to install any package that can be found on the official Nix package registry. This give us the ability to install any language interpreter or binary we want, provided said language is able to execute arbitrary code. With minimal work, we'll be able to implement multiple languages in our compute backend and execute them through our API.
- Thu, Jun 24, 2021
Dynamic version for Nix derivations
UPDATE - 05/07/2021 Thanks to Travis Cardwell for letting us know that Nix requires the version part of the derivation name to start with a digit. The post has been upated from its original version to include this requirement. When you open a repl, we link it to a Docker container in the cloud. As we've started supporting more and more languages over the years, the size of that Docker image has exploded in size. It can take us up to a week to safely deploy! Any update, no matter the size, to our tooling can't be shipped to our users as fast as we'd like. This is where our migration to Nix comes in. We are now building these tools in our CI pipelines as Nix packages. We can reduce the size of our image to its minimum and provide all our tools and languages through Nix, on demand. One drawback of Nix for us is the need to specify the version in the derivation code (Like you would do in the package.json in NPM for example), rather than rely on image tagging. Before we could move forward, we had to solve one of the harder problems in computer science: versioning. We settled on using the commit short sha (first 7 characters of a commit's ID) as the version for our tools. However, we needed to go edit the default.nix file manually in the tool's repository every time we needed to publish a version. This wasn't providing us with the speed and flexibility we wanted, and we wondered if it was possible to generate the version automatically. After all, Nix is a fully fledged programming language, so that should be doable? It is, but it was not as easy as we thought. Starting with a Nix package One great thing about Nix is that its entire library of standard packages is available in a very easy to parse GitHub repository. A quick search led me to this package in particular. That code does almost the same thing we're hoping to do: call a runCommand function and execute git rev-parse --short there. With this in hand, I trimmed the code and wrote a quick function to get the short sha.
 Mon, May 24, 2021
Mon, May 24, 2021How we went from supporting 50 languages to all of them
At Replit, we want to give our users the most powerful, flexible, and easy-to-get-started coding environment. However, it has been limiting because we only support a fixed set of languages and OS packages, some of which are outdated. Ideally, users should be able to use any language and install any package with minimal fuss. That's why today, we're announcing that we've incorporated Nix in our infrastructure to give users access to over 30,000 OS packages instantly. The environment repls run in has long been a static world. We build a pre-baked OS image to fit all our languages. This gives us a lot of leeway to make repls super fast, but the underlying operating system repls run in is completely immutable. To remedy the situation we've been maintaining an ever growing OS image, if users can't install any packages we'll just install every package! As awesome as this sounds it has become a huge burden to maintain. Every new package creates a new exciting way things can break. Over time, it became clear that maintaining a single, massive docker image was not sustainable. We came across Nix which is a declarative, reproducable OS package manager. Due to Nix's design its package store is highly cacheable and allows for building environments in a composable way. Using the Nix programming language you can specify the dependencies for your development environment and Nix will build the environment for you. We believe this is a great fit for Replit as it allows our users to build endless combinations of development environments without us having to maintain a monolithic docker image. With Nix on Replit, see how easily you can create a Zig environment in a few seconds. We create a replit.nix file to tell the repl which Nix packages should be available when we run. Then we use .replit to control what the run button does. And voila we have a new language: How it works
 Wed, Apr 28, 2021
Wed, Apr 28, 2021Why We Built Our Own DNS Infrastructure
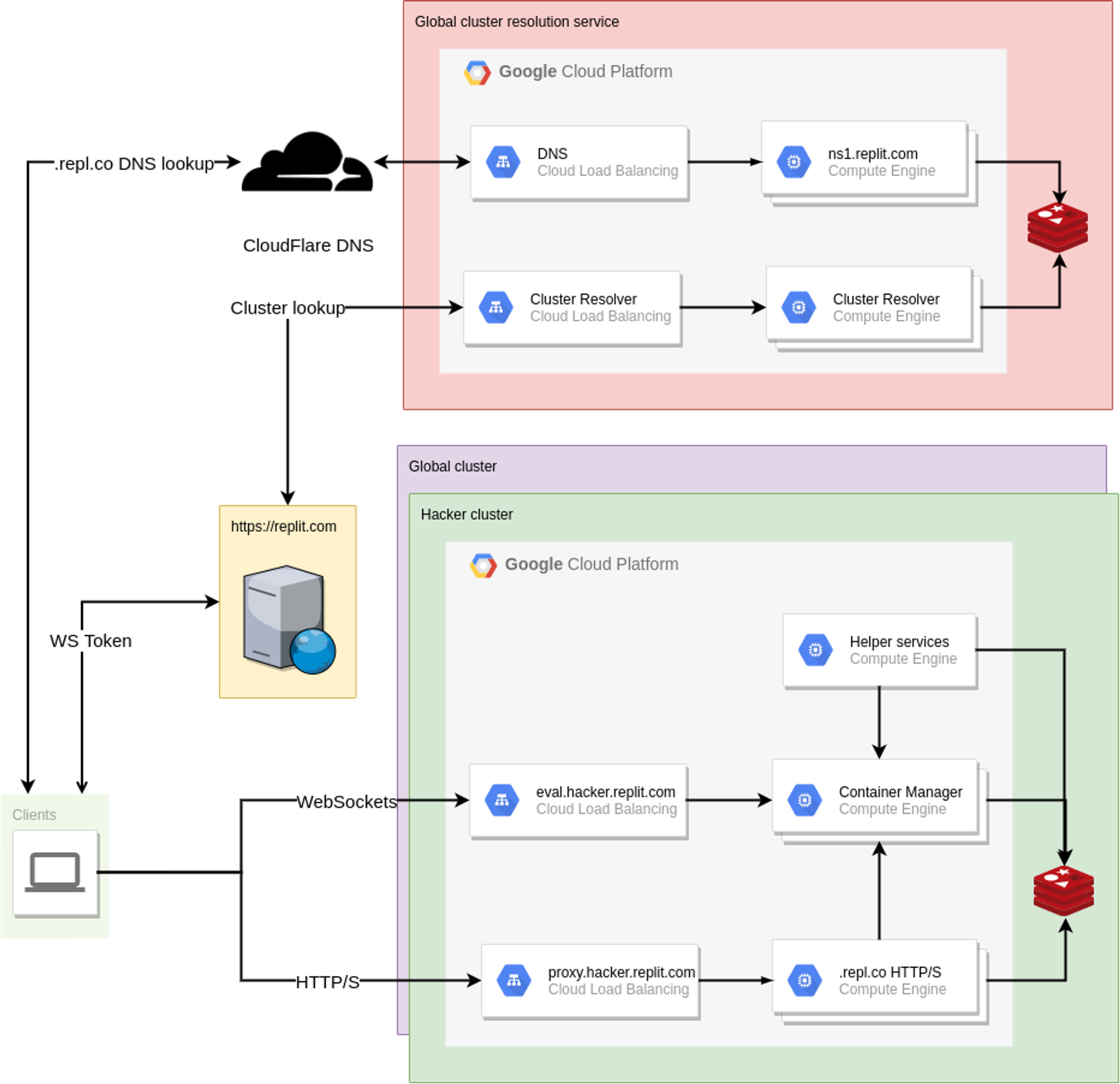
This post is part of a series about the wonderful world of clusters. Check out the first post for an overview of what clusters are all about. In this post we will take a peek under the hood of our hosting infrastructure and walk through how we made hosting work in a multi-cluster world. Hosting overview If you didn't already know, you can host web servers right on Replit.com. Just create a new repl and spin up a web server using Flask, Express, or your favorite web framework. We automatically detect the web server and open a webview in the workspace. Your repls are automatically accessible via a *.repl.co domain and usually looks something like <repl name>.<user>.repl.co. In fact, this blog is hosted on a repl. On the backend, a proxy service handles proxying HTTP requests to the proper repl based on the host (domain name) of the request. This service shares a database with the container management service so that it knows which repl container to proxy HTTP requests to. Pre-Clustered World Our pre-cluster hosting setup was rather simple, we ran multiple instances of our proxy service behind a single load balancer. The load balancer had a single static IP address; both repl.co and *.repl.co had an A record with the static IP address of the load balancer. For an intro to DNS, check out howdns.works
- Fri, Mar 26, 2021
Welcome to the Wonderful World of Clusters
Having a solid foundation is critical for us to be able to fulfill our mission of making programming more accessible, more creative, and more fun. We did a great job of making the platform more stable during last year, but every now and then we would still run into unforeseen problems that cascaded into other parts of the platform, producing a bad experience for everyone. So back in October (just a few weeks after I joined the team) when we had 2 load-related site-wide outages within a week, we knew it was time to do a major overhaul of how our infrastructure handles traffic. And now today, we're announcing that as a side effect of that infrastructure change, Hacker repls now run in newer, more powerful machines, which means that we'll have more room to grow and experiment with more benefits for Hackers (and you might find that things feel a little bit snappier lately). This is the first of a three-part series of blogposts on how we rebuilt our infrastructure over the course of ~5 months. Introducing a new failure domain The original goal of this endeavor was simple, in theory: split the Replit infrastructure into multiple failure domains, so that when (not if) the next incident occurs, it only affects a subset of the users instead of all of them. There are multiple strategies to do so, and we chose to move Hackers to their own failure domain. But what does this split entail? Prior to this change, our backend infrastructure was relatively simple: a Google Compute Managed Instance Group of VMs that run containers, and another one that serves HTTP traffic on .repl.co domains. So in theory if we take the right-hand side of the diagram and make multiple copies of it, treating each one as a completely independent cluster, we solve the problem. Mission accomplished, right? Not quite: clients now need to know where to make their requests to, since they will now need to hit different hostnames depending on which cluster their repls are (since they are now completely independent after all). Clients that wanted to connect to their repl through the workspace were already required to contact the replit.com web server to get an auth token for the WebSocket connection anyways, so it would make sense for the web server to be the source of truth about the repl->cluster mapping. But what about hosting? All repls get a .repl.co domain, and users can CNAME them to be able to get to their app. At this point, the problem started looking very DNS-shaped, and that's kind of what we ended up doing: an external cluster resolution service, that can be used by both the Replit.com web server and individual clients trying to access their apps!
- Fri, Mar 19, 2021
Introducing the Python package cache
Figuring out how to install third-party libraries can derail people from learning to code or starting a new side project. We built the Universal Package Manager (UPM for short) to save people from having to think about package installation at all. Just import the library, press run, and UPM will install it into your repl! Every time you run a repl or a repl wakes up, UPM checks to see if it needs to download and install any dependencies. This is handy (no matter what's gone inside your repl, it will always have the dependencies it needs) but slow: UPM needs to download typically tens of megabytes worth of packages, extract them on the local filesystem, and sometimes also pre-compile them for better runtime performance. Or at least it used to be slow until yesterday when we enabled the Python package cache, so now the most popular Python packages are pre-populated in pip's cache (/home/runner/.cache/pip), so the download step is going to be mostly gone for the vast majority of Python repls! It also uses pre-built wheels as much as possible to avoid even having to pre-compile code. How does it work? We had two goals in mind when we started designing this: it should be as transparent as possible, which meant that users would still be able to add packages to the local cache while avoiding copying files around (which would have defeated the purpose of using a cache in the first place), and
 Sun, Jan 31, 2021
Sun, Jan 31, 2021Killing Containers at Scale
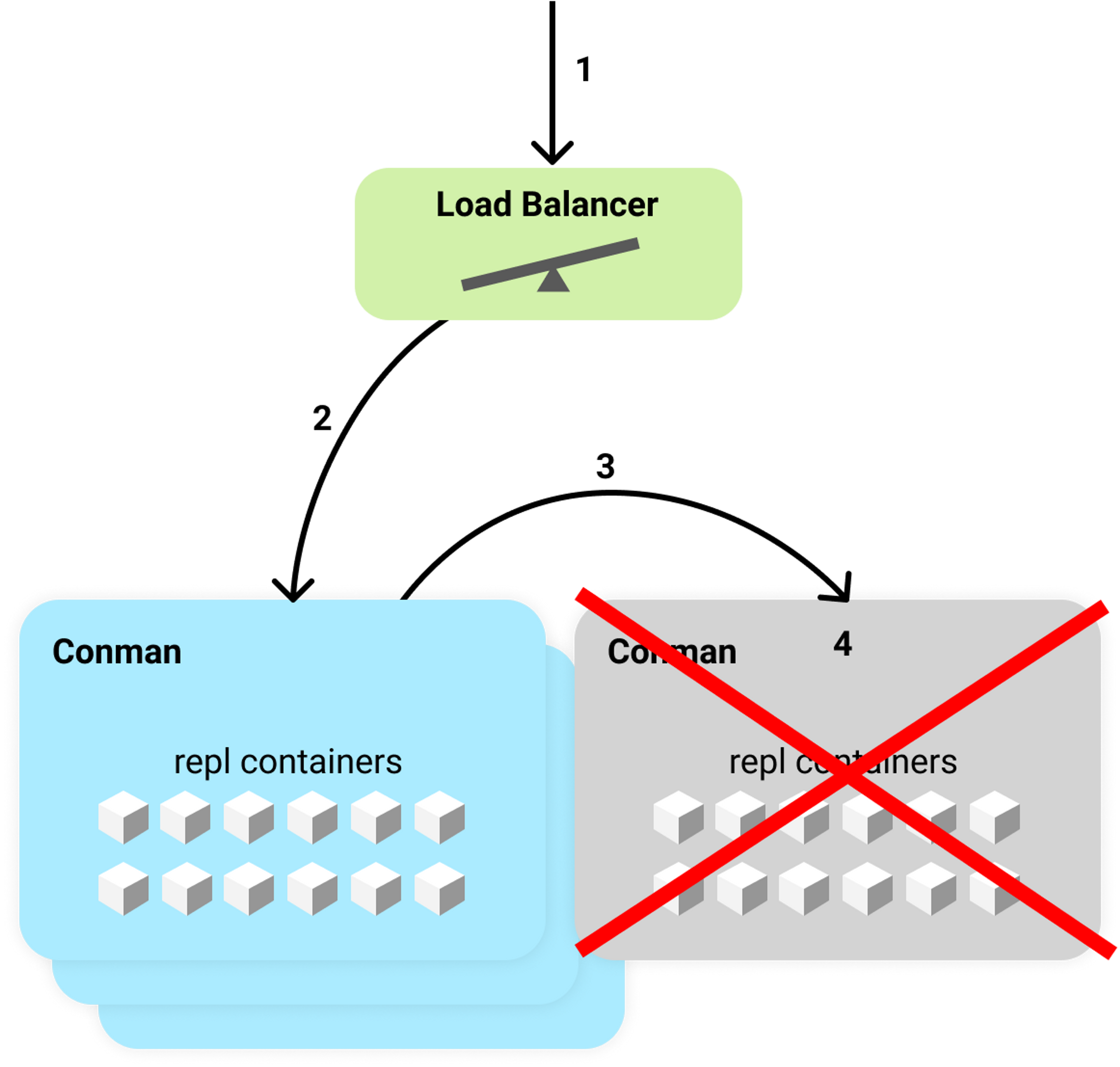
To make it so that anyone with a web browser can code on Replit, our backend infrastructures runs on preemptible VMs. That means the computer running your code can shutdown at any time! We've made it really fast for repls to reconnect when that happens. Despite our best efforts, though, people had been seeing repls stuck connecting for a long time. After some profiling and digging into the Docker source code, we found and fixed the problem. Our session connection error rate dropped from 3% to under 0.5% and our 99th percentile session boot time dropped from 2 minutes to 15 seconds. There were many different causes of stuck repls, varying from: unhealthy machines, race conditions that lead to deadlock, and slow container shutdowns. This post focuses how we fixed the last cause, slow container shutdowns. Slow container shutdowns affected nearly everyone using the platform and would cause a repl to be inaccesible for up to a minute. Replit Architecture Before going in depth on fixing slow container shutdowns, you'll need some knowledge of Replit's architecture. When you open a repl, the browser opens a websocket connection to a Docker container running on a preemptible VM. Each of the VMs run something we call conman, which is short for container manager. We must ensure that there is only a single container per repl at anytime. The container is used to facilitate multiplayer features, so its important that every user in the repl connects to the same container.
- Sun, Sep 20, 2020
Focusing on a solid foundation
At Repl.it, our mission is to make programming more accessible, more creative, and more fun. A place away from the modern software development grind. It’s an ambitious mission, and it's already resonated with millions of coders who followed their creative energy to build great apps, like repl.email, a free email service built and hosted entirely on Repl.it and available to anyone with a Repl.it account. Repl.it has grown so much in the past few years: To give you an idea of the scale we're operating on, we now serve 120k concurrent containers. That is 120,000 computers started at once We doubled our team every year for the past 4 years: 2^4 = 16, and are still hiring Repl.it went from a simple online REPL to a world-leading collaborative coding environment focused on learning and prototyping However, with growth comes problems: