
This post is part of a series about the wonderful world of clusters. Check out the first post for an overview of what clusters are all about. In this post we will take a peek under the hood of our hosting infrastructure and walk through how we made hosting work in a multi-cluster world.
Hosting overview
If you didn't already know, you can host web servers right on Replit.com. Just create a new repl and spin up a web server using Flask, Express, or your favorite web framework. We automatically detect the web server and open a webview in the workspace. Your repls are automatically accessible via a *.repl.co domain and usually looks something like <repl name>.<user>.repl.co. In fact, this blog is hosted on a repl.
On the backend, a proxy service handles proxying HTTP requests to the proper repl based on the host (domain name) of the request. This service shares a database with the container management service so that it knows which repl container to proxy HTTP requests to.
Pre-Clustered World
Our pre-cluster hosting setup was rather simple, we ran multiple instances of our proxy service behind a single load balancer. The load balancer had a single static IP address; both repl.co and *.repl.co had an A record with the static IP address of the load balancer. For an intro to DNS, check out howdns.works
Clusterization
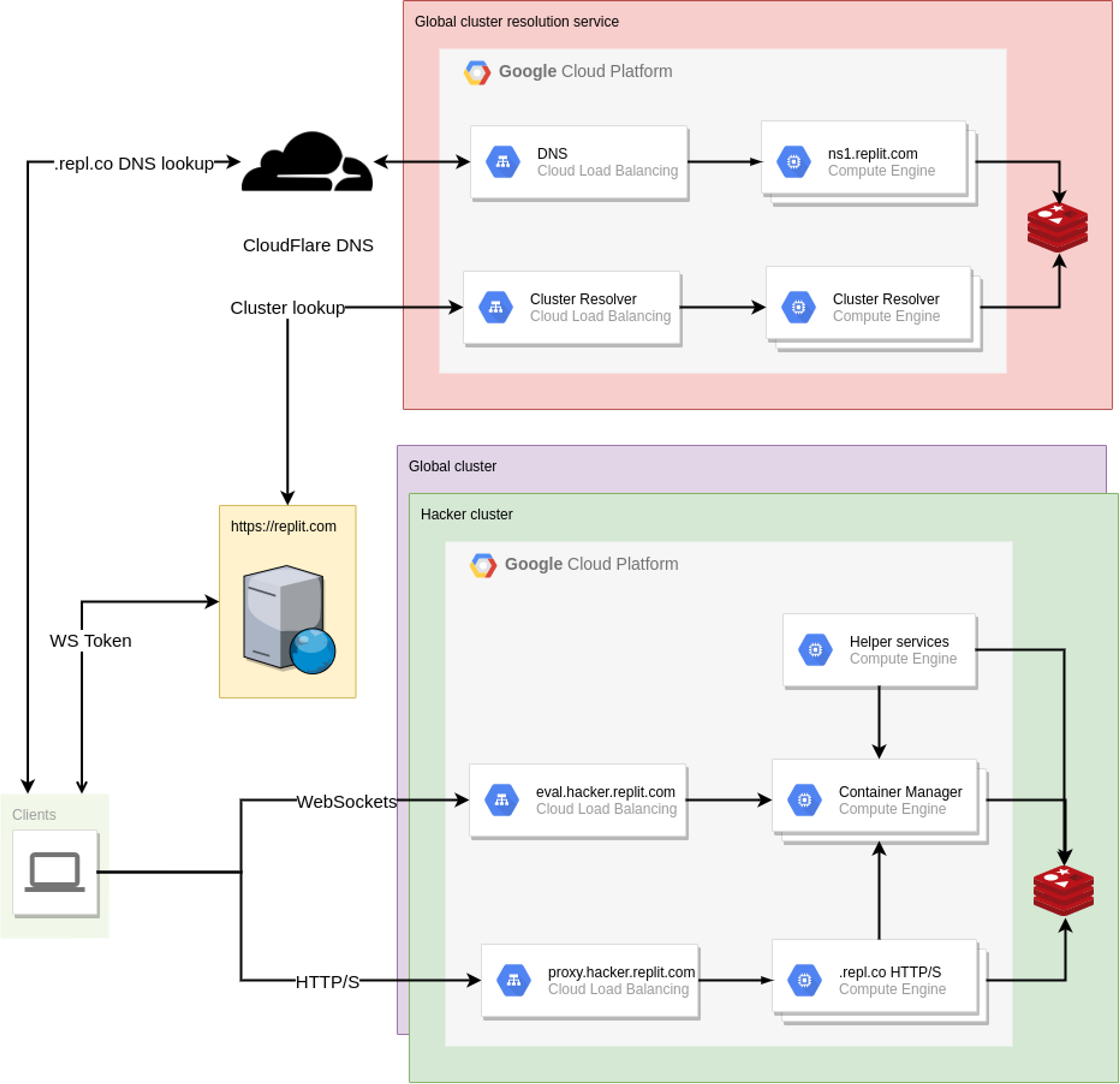
As mentioned before, the proxy relies on sharing a database with the container management service. In the cluster world, each cluster gets its own database. Each cluster gets its own set of proxy instances which only have access to the database in that cluster. In the diagram below (from the first post in this series), you'll notice that each cluster has its own set of proxy instances. The proxies are labelled as .replco HTTP/S:
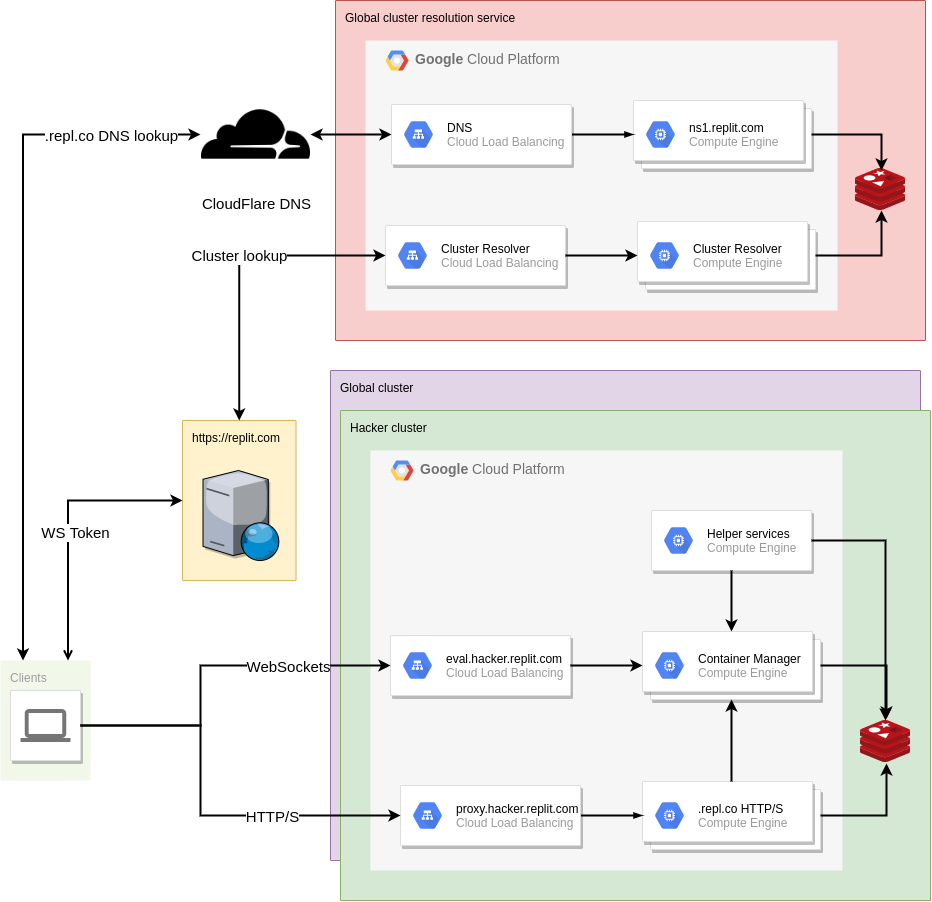
We will need to add some new functionality to handle routing requests to the correct cluster so the request lands on a proxy in the same cluster of the destination repl container. For example: Let's say user replbot is in cluster A and user mark is in cluster B. If replbot has a repl called blog, we must route HTTP requests to blog.replbot.repl.co to a proxy in cluster A whereas HTTP requests to Mark's coolgame.mark.repl.co must be routed to a proxy in cluster B.
Our first thought was to add a new proxy service as another layer of indirection to reverse-proxy requests to the proxies in the correct cluster. We referred to this as the "meta-proxy". Unfortunately requests would now have 2 extra hops before reaching the repl:
client -- coolgame.mark.repl.co --> meta-proxy load balancer --> meta-proxy instance --\
/-------------------------------------------------------------------------------------/
\--> (Cluster B) proxy load balancer --> (Cluster B) proxy instance --> repl container
This solution wasn't very satisfactory and after more thinking we had the wild idea of running our own authoritative DNS name server which handles DNS lookups for *.repl.co domains. It would respond with an A record with the IP address of the proxy load balancer in the correct cluster. With this approach we make hosting cluster-aware with nearly no additional overhead. No extra hops are required when making a request to a repl as we already had to do a DNS lookup.
Building the DNS server
Our authoritative name server is implemented in Go using the wonderful miekg/dns package. Its job is pretty simple: given a *.repl.co domain (ie. coolgame.mark.repl.co), figure out the repl from the domain, lookup the cluster for that repl, respond with the IP address of the proxy load balancer in that cluster.
In addition to handling A record lookups for *.repl.co, it also needs to handle DNS-01 challenges so we can generate wildcard TLS certificates. You can read more about our TLS certificate generation in HTTPS by default. As a first pass, we delegate all DNS-01 challenges to a special validation zone managed by GCP. In practice this means we CNAME any _acme-challenge.* to <domain>.validation.replit.com. However, we are in the process of handling DNS-01 challenges directly so we can reduce the time it takes to generate TLS certificates.
Tombstones
If you know anything about DNS, you probably know that it can take a while for changes to propagate everywhere. We use low TTLs on our records (60s at the time of writing), but sometimes TTLs are ignored. So what happens when a repl moves to a cluster and the updated DNS record hasn't propagated yet? Requests will still go to the old cluster. We want to handle this case so hosting doesn't break every time a repl moves to a different cluster. We use tombstones in the old cluster to mark that a repl has been transferred to a new cluster. If a proxy finds a tombstone for a repl, it transparently proxies the request to the cluster that is stored in the tombstone. This allows us to completely transparently migrate repls between clusters.
Custom Domains
We also offer linking custom domains to your repl. Up to this point we've only talked about the DNS server handling *.repl.co domains, so how do custom domains fit in? When linking custom domains, we've always had users add a CNAME record to <repl id>.repl.co. Our DNS server understands domains of the form <repl id>.repl.co so custom domains will automatically point to the correct cluster.
Wrapping Up
Our DNS infrastructure now handles all queries for *.repl.co and partitions web traffic between all of our clusters. Between our DNS infrastructure and adding tombstones to the proxy, our hosting infrastructure is now fully cluster-aware.
Splitting our infrastructure into clusters not only introduces more failure domains, it also allows us to use different configurations per cluster. For example, hacker users run in their own cluster with more powerful VMs.
I hope you enjoyed learning more about our hosting infrastructure and in our next post you'll hear from Zach Anderson about our new system for deploying to multiple clusters. Happy repling!
P.S. If this kind of infrastucture is interesting to you, we're hiring!