
 Mon, Sep 16, 2024
Mon, Sep 16, 2024Introducing Replit Agent
Last week, we launched Replit Agent, our AI system that can create and deploy applications. Now, with only a few sentences and a few minutes, you can take an application from idea to deployment. You can think about the Agent like a pair programmer. It configures your development environment, installs dependencies, and executes code. From your laptop or the Replit mobile app, the Agent is changing how our users build software. If you'd like to learn more, we've compiled some of our favorite examples, tutorials, and articles on the agent so far.
 Wed, Aug 14, 2024
Wed, Aug 14, 2024How Replit makes sense of code at scale
For any company making creative tools, being able to tell what its most engaged users are building on the platform is critical. When the bound of what’s possible to create is effectively limitless, like with code, sophisticated data is needed to answer this deceivingly simple question. For this reason, at Replit we built an infrastructure that leverages some of the richest coding data in the industry.
 Tue, Apr 2, 2024
Tue, Apr 2, 2024Building LLMs for Code Repair
Introduction At Replit, we are rethinking the developer experience with AI as a first-class citizen of the development environment. Towards this vision, we are tightly integrating AI tools with our IDE. Currently, LLMs specialized for programming are trained with a mixture of source code and relevant natural languages, such as GitHub issues and StackExchange posts. These models are not trained to interact directly with the development environment and, therefore, have limited ability to understand events or use tools within Replit. We believe that by training models native to Replit, we can create more powerful AI tools for developers. A simple example of a Replit-native model takes a session event as input and returns a well-defined response. We set out to identify a scenario where we could develop a model that could also become a useful tool for our current developers and settled on code repair. Developers spend a significant fraction of their time fixing bugs in software. In 2018, when Microsoft released “A Common Protocol for Languages,” Replit began supporting the Language Server Protocol. Since then, the LSP has helped millions using Replit to find errors in their code. This puts LSP diagnostics among our most common events, with hundreds of millions per day. However, while the LSP identifies errors, it can only provide fixes in limited cases. In fact, only 10% of LSP diagnostic messages in Python projects on Replit have associated fixes. Given the abundance of training data, repairing code errors using LSP diagnostics is therefore the ideal setting to build our first Replit-native AI model. Methodology Data
 Wed, Feb 14, 2024
Wed, Feb 14, 2024Introducing Multiplayer AI Chat
One of our core beliefs at Replit is that multiplayer collaboration makes building software more creative and efficient. After introducing Replit AI for All last year, we heard from our users how transformative AI has been to their development workflows. Today, we are announcing several updates to our AI Chat product, but most importantly, we are bringing the multiplayer power of Replit to AI. We will continue to offer AI to all users, with advanced models available for Replit Core members, but now with the ability to collaborate with others in multiple, persistent chat sessions. What's new? Multi-session chat with persistence You can now create and manage multiple chat sessions when interacting with Replit AI. Creating multiple threads with our AI products allows you to switch between asking for explanations about files in your codebase, generating code for a new feature, and debugging, all without losing your progress. This was a top feature request, and we’re excited to bring multi-session functionality to the platform so developers can stay organized and engaged, all within the same familiar workspace UI. Collaboration and multiplayer
 Wed, Dec 20, 2023
Wed, Dec 20, 20239 AI Templates and Playgrounds for Your Business
Integrating the latest AI tools into your team can be a significant advantage. However, assessing these tools and setting them up to run can take time and effort. Whether you’re testing a new large language model or building a prototype with a vector database, chances are somebody has already developed a similar AI tool. Increasing developer productivity is a cornerstone of Replit, and we want to give you the tools to elevate your team and quickly incorporate the latest AI developer tools into your business. Fork one of the AI templates below and customize it for your requirements. Once you’re finished, you can deploy it with just a few clicks from Replit and share it with your team. In this post, we’ll highlight some of the top templates on Replit that can help you explore and integrate the latest AI developer tools. 1. Gemini vs GPT-4 Easily integrate and compare the two top-performing LLMs with this starter code. Each of these templates contains the proper way to make API calls to Google’s Gemini API in JavaScript and Python.
 Tue, Oct 10, 2023
Tue, Oct 10, 2023Replit’s new AI Model now available on Hugging Face
At Replit, our mission is to empower the next billion software creators. Yesterday, we strengthened our commitment by announcing that Replit AI is now free for all users. Over the past year, we’ve witnessed the transformative power of building software collaboratively with the power of AI. We believe AI will be part of every software developer’s toolkit and we’re excited to provide Replit AI for free to our 25+ million developer community. To accompany AI for all, we’re releasing our new code generation language model Replit Code V1.5 3B on Hugging Face. We believe in open source language models – anyone can use it as a foundational model for application-specific fine-tuning without strict limitations on commercial use. Key Features Extensive Permissively Licensed Training Data: Trained on 1 trillion tokens of code from permissively licensed code from the Stack dataset and publicly available dev-oriented content from StackExchange. State of the Art Results: Leading HumanEval and Multi-PLe evaluation scores for a 3B code completion model. Broad Multi-Language Support: Encompasses Replit's top 30 programming languages with a custom trained 32K vocabulary for high performance and coverage.
 Mon, Oct 9, 2023
Mon, Oct 9, 2023Announcing Replit AI for All
For every human endeavor, there inevitably arrives a moment when an innovation profoundly elevates the potential for productivity. For instance, communication was revolutionized by the invention of the printing press, and later, the Internet. After decades of steady progress, software is witnessing its disruption phase as well -- AI is redefining the whole software development lifecycle. AI is one of the key ingredients to go from idea to software, fast -- we witnessed this from over a year of experience in pioneering Ghostwriter Autocomplete and Chat. At Replit, we are on a mission to empower the next billion software creators. Over time, we gained full conviction that such a mission can’t be accomplished without putting our AI features in the hands of every Replit developer. Today, we’re making Replit AI available for everyone. Code completion and AI code assistance are now enabled by default, and available to 23M developers (and counting). Developers on the free plan will have access to our basic AI features, while Pro users will retain exclusive access to the most powerful AI models and advanced features. This was no easy feat, and required not only all our expertise in scaling distributed systems, but also training low-latency LLMs to serve Replit’s compute-heavy AI workloads. Emboldened by the strong performance we obtained with training and serving replit-code-v1-3b, today we are also releasing replit-code-v1.5-3b, a state-of-the-art 3B LLM trained on 1T tokens from a code-heavy pretraining mixture. The dataset includes 30 programming languages and a dev-oriented subset of StackExchange. We will gradually roll out our new code LLM in the next few days, making code completion on the Replit AI code editor even more powerful. Our roadmap for the near future can be summarized in one sentence: AI will redefine every single Replit feature. It won’t be necessary to mention that AI plays a fundamental role every time software is being edited or deployed -- soon we will take it for granted.
 Mon, Sep 18, 2023
Mon, Sep 18, 2023AI Agent Code Execution API
Lately, there has been a proliferation of new ways to leverage Large Language Models (LLMs) to do all sorts of things that were previously thought infeasible. But the current generation of LLMs still have limitations: they are not able to get exact answers to questions that require specific kinds of reasoning (solving some math questions, for example); similarly, they cannot dynamically react to recent knowledge beyond a particular context window (anything that happened after their training cutoff window comes to mind). Despite these shortcomings, progress has not stopped: there have been advances in building systems around LLMs to augment their capabilities so that their weaknesses are no longer limitations. We are now in an age where AI agents can interact with multiple underlying LLMs optimized for different aspects of a complex workflow. We are truly living in exciting times! Code execution applications LLMs are pretty good at generating algorithms in the form of code, and the most prominent application of that particular task has been coding assistants. But a more significant use case that applies to everyone (not just software engineers) is the ability to outsource other kinds of reasoning. One way to do that is in terms of sequences of instructions to solve a problem, and that sounds pretty much like the textbook definition of an algorithm. Currently, doing that at a production-level scale is challenging because leveraging LLMs' code generation capabilities for reasoning involves running untrusted code, which is difficult for most users. Providing an easy path for AI Agents to evaluate code in a sandboxed environment so that any accidents or mistakes would not be catastrophic will unlock all sorts of new use cases. And we already see the community building upon this idea in projects like open-interpreter. Two options But how should this sandbox behave? We have seen examples of multiple use cases. Google's Bard recently released "implicit code execution,” which seems to be used primarily for math problems. The problem is boiled down to computing the evaluation of a function over a single input and then returning the result. As such, it is inherently stateless and should be able to handle a high volume of requests at low latency. On the other hand, ChatGPT sessions could benefit from a more stateful execution, where there is a complete project with added files and dependencies, and outputs that can be fetched later. The project can then evolve throughout the session to minimize the amount of context needed to keep track of the state. With this use case, it's fine for the server to take a bit longer to initialize since the project will be maintained for the duration of the chat session.
 Thu, Jul 13, 2023
Thu, Jul 13, 2023State of AI Development: 34x growth in AI projects, OpenAI's dominance, the rise of open-source, and more
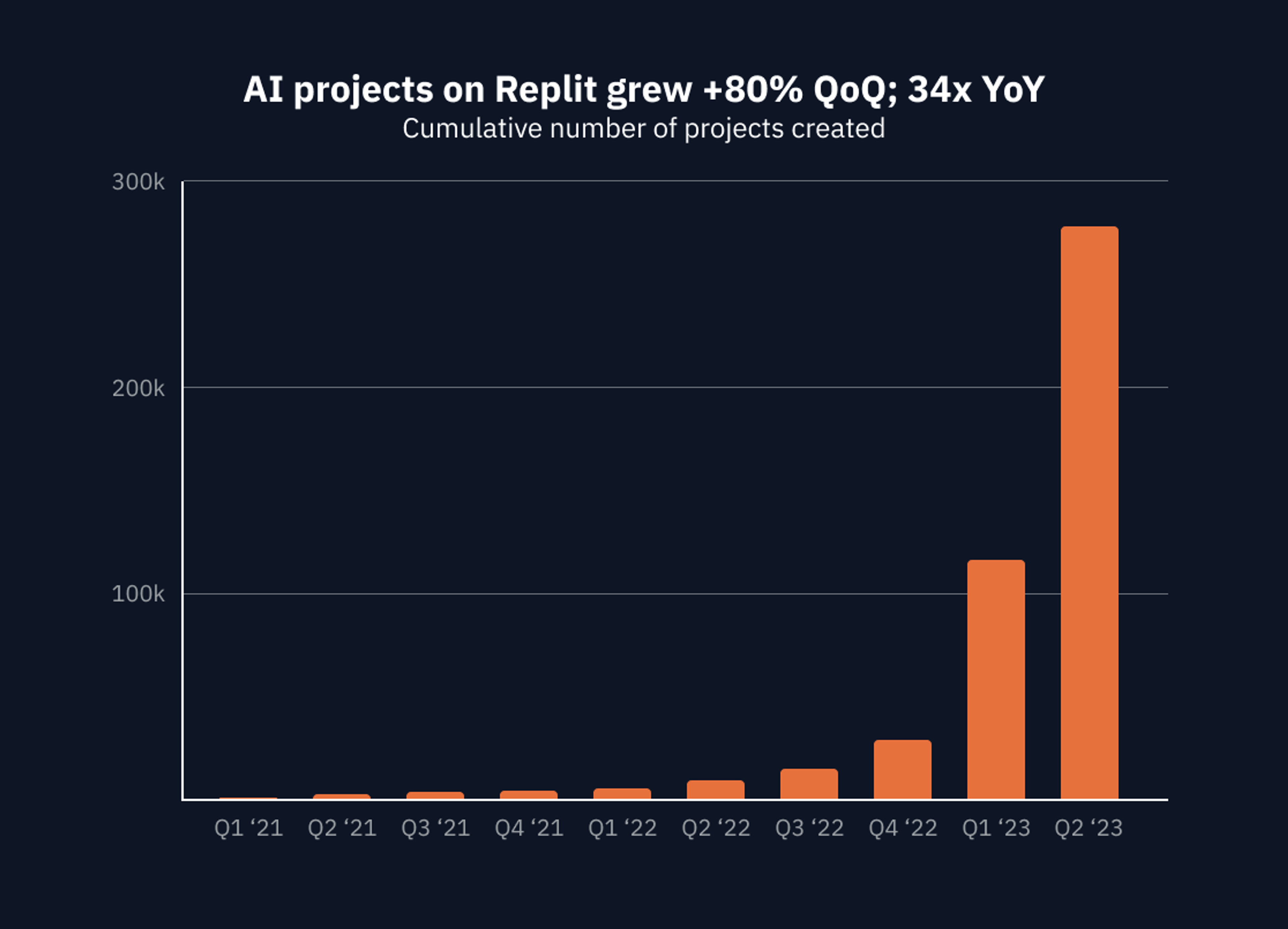
With the introduction of Large Language Models (LLMs), for the first time, Machine Learning (ML) and Artificial Intelligence (AI) became accessible to everyday developers. Apps that feel magical, even software that was practically impossible to build by big technology companies with billions in R&D spend, suddenly became not only possibly, but a joy to build and share. The surge in building with AI started in 2021, grew rapidly in 2022, and exploded in the first half of 2023. The speed of development has increased with more LLM providers (e.g., Google, OpenAI, Cohere, Anthropic) and developer tools (e.g., ChromaDB, LangChain). In parallel, natural language interfaces to generate code have made building accessible to more people than ever. Throughout this boom Replit has grown to become the central platform for AI development. Tools like ChatGPT can generate code, but creators still need infrastructure to run it. On Replit, you can create a development environment (Repl) in seconds in any language or framework which comes with an active Linux container on Google Cloud, an editor complete with the necessary tools to start building, including a customizable Workspace, extensions, and Ghostwriter: an AI pair programmer that has project context and can actively help developers debug. Deployments allowed developers to ship their apps in secure and scalable cloud environments. Given our central role in the AI wave, we wanted to share some stats with the community on the state of AI development. Building with AI Since Q4 of 2022, we have seen an explosion in AI projects. At the end of Q2 ‘23, there were almost 300,000 distinct projects that were AI related. By contrast, a search of GitHub shows only ~33k OpenAI repositories over the same time period.
 Mon, Jun 5, 2023
Mon, Jun 5, 2023Replit AI Manifesto
Amjad Masad, CEO: I'm excited to welcome Michele Catasta to the Replit team as our VP of AI. Michele joins us from Google, where he was Head of Applied Research at Google Labs and, before that, Google X, where he researched Large Language Models applied to code. Michele has a Ph.D. in Computer Science and was Research Scientist and Instructor in AI at Stanford University. This manifesto is a culmination of a conversation Michele and I have had for over a year on the future of AI and its impact on the software industry: “People who are really serious about software should make their own hardware.” [1982] More than 40 years later, Alan Kay’s quote still sounds as relevant as it gets – no wonder he is recognized as one of the most influential pioneers of our industry. As a matter of fact, over the past few decades software and hardware worked in conjunction to dramatically augment human intelligence. Steve Jobs celebrated Alan’s quote in his famous 2007 keynote, right after launching the very first iPhone – possibly one of Steve’s mottos, considering how Apple built its reputation and massive success story on unprecedented software/hardware integration. At Replit, our mission is to empower the next billion software creators. Our users build software collaboratively with the power of AI, on any device, without spending a second on setup. We accomplished that by creating from the ground up a delightful developer experience. The Replit development environment allows our users to focus solely on writing software, while most of the hardware (and Cloud computing) complexities are carefully hidden away.
 Mon, May 1, 2023
Mon, May 1, 2023Copyright Law in the Age of AI: The Role of Licensing in Replit's Development
Thousands of unique users code in Replit every day. Few of them probably give much thought to the copyright that attaches to their code. They might be surprised to learn that copyright – specifically, the way that Repls are licensed – is fundamental to the way that Replit works. As the AI software revolution proceeds apace, copyright law is again playing a fundamental role in how it develops – and in how Replit brings the benefits of this technology to our users. We’ll explain all in this blog post. But before we get there, time for a history lesson. A brief history of software licensing The relationship between copyright and computer software wasn’t always obvious, even to lawyers. Early versions of the Unix operating system, developed at Bell Labs in the 1970s, were distributed freely along with their source code, so that the recipients of the code could hack on it. Decades later this led to a copyright lawsuit, but following its settlement, entirely free distributions of Unix became legally available, with their components licensed under free software licenses such as the MIT license.
 Tue, Apr 18, 2023
Tue, Apr 18, 2023How to train your own Large Language Models
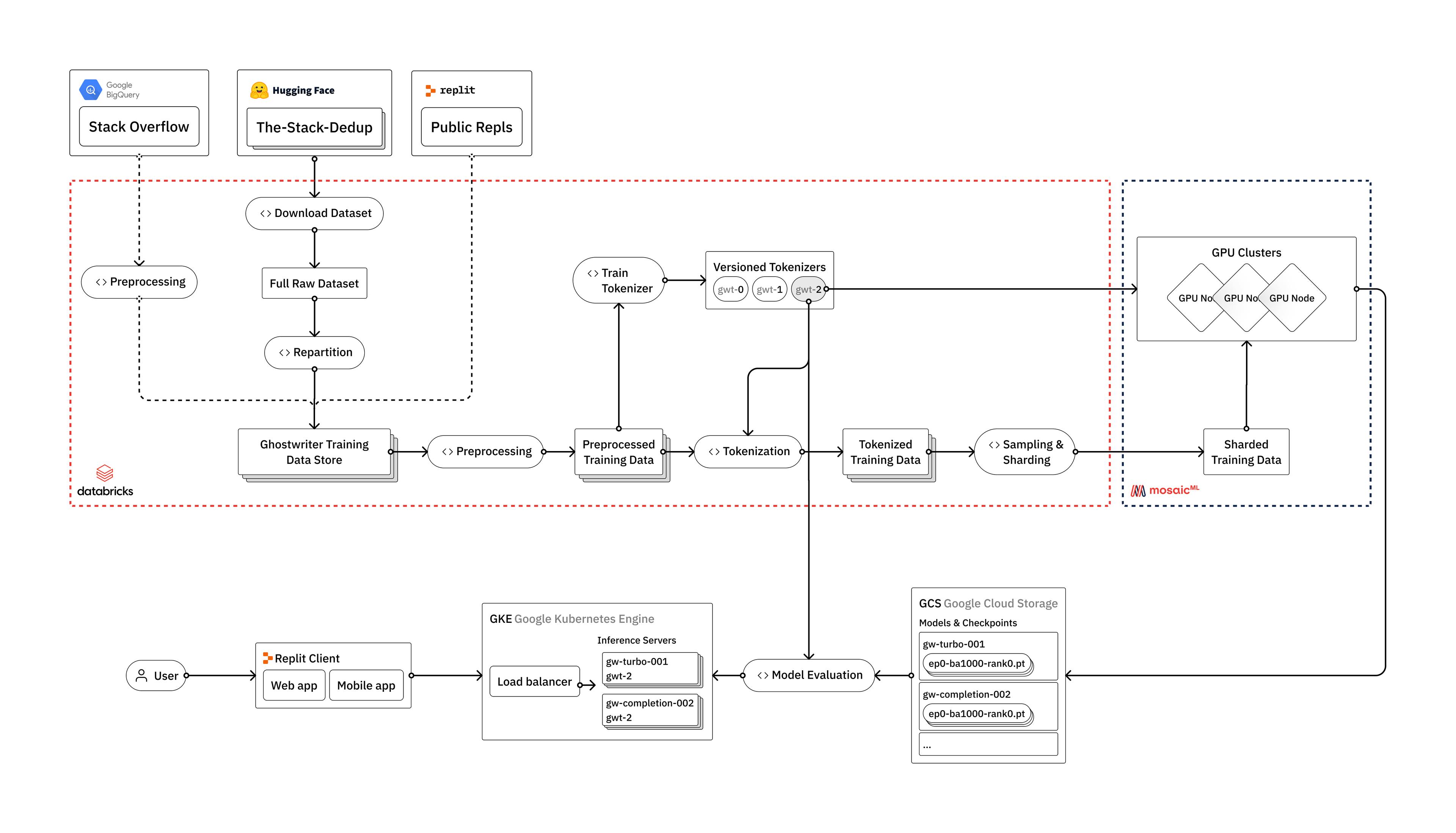
Learn how Replit trains Large Language Models (LLMs) using Databricks, Hugging Face, and MosaicML Introduction Large Language Models, like OpenAI's GPT-4 or Google's PaLM, have taken the world of artificial intelligence by storm. Yet most companies don't currently have the ability to train these models, and are completely reliant on only a handful of large tech firms as providers of the technology. At Replit, we've invested heavily in the infrastructure required to train our own Large Language Models from scratch. In this blog post, we'll provide an overview of how we train LLMs, from raw data to deployment in a user-facing production environment. We'll discuss the engineering challenges we face along the way, and how we leverage the vendors that we believe make up the modern LLM stack: Databricks, Hugging Face, and MosaicML. While our models are primarily intended for the use case of code generation, the techniques and lessons discussed are applicable to all types of LLMs, including general language models. We plan to dive deeper into the gritty details of our process in a series of blog posts over the coming weeks and months. Why train your own LLMs?
 Wed, Apr 5, 2023
Wed, Apr 5, 2023Replit + Chroma: AI for the next billion software creators
Guest post by Chroma Today we’re announcing the Chroma template for Replit, the next step towards bringing the power of AI application development to the next billion software creators. With the Chroma template, developers can easily create AI applications with state and memory. Want to make ChatGPT for your email? Or chat to your textbooks while you study? Want LLMs to know about the latest news stories? Together with Replit, Chroma makes all that and more easy.
 Thu, Mar 30, 2023
Thu, Mar 30, 2023Applications of Generative AI Webinar
In case you missed it, last week we hosted legendary AI Researcher Jim Fan from NVIDIA AI for an incredible discussion on all things Generative AI. During a one-hour conversation with Amjad Masad, CEO and co-founder of Replit, and Michele Catasta, Replit's ML Advisor, the group discussed the recent advancements in AI and the potential impact of multi-modality on the field. Event Recap Jim Fan has worked in AI for a decade and has collaborated with several prominent AI researchers. He highlights the growth of AI from image recognition to large language models like GPT-4. Amjad shares his background in developer tools and his excitement about applying machine learning and statistical approaches to code. 2:50 - The discussion starts with the recent NVIDIA GTC event, with Jim describing NVIDIA's transition from a hardware provider to an enterprise-focused AI provider. He is mainly excited about NVIDIA AI Foundations, which offer customization services that allow enterprises to create unique use cases with multimodal language models. These models will also help incorporate images, videos, and 3D data into AI systems. 5:45 - Michele highlights the importance of multi-modality and how it grants superpowers in communications with computers. Jim envisions a range of possibilities with multi-modal language models, including being able to interact with more natural human input, enhancing note-taking, and automating home decoration plans.
 Mon, Mar 27, 2023
Mon, Mar 27, 2023Replit and Google Cloud Partner to Advance Generative AI for Software Development
Note: Since this announcement, Replit AI has launched a series of new features and updates. For most current information, check out our Replit AI page. Original press release here Under the new partnership, Replit developers will get access to Google Cloud infrastructure, services, and foundation models via Ghostwriter, Replit's software development AI, while Google Cloud and Workspace developers will get access to Replit’s collaborative code editing platform. The collaboration will accelerate the creation of generative AI applications and underscores Google Cloud's commitment to nurturing the most open ecosystem for generative AI. For Replit, already 20 million developers strong, this partnership with Google Cloud is its next move in realizing its mission to empower the next 1 billion software creators.