Introduction
At Replit, we are rethinking the developer experience with AI as a first-class citizen of the development environment. Towards this vision, we are tightly integrating AI tools with our IDE. Currently, LLMs specialized for programming are trained with a mixture of source code and relevant natural languages, such as GitHub issues and StackExchange posts. These models are not trained to interact directly with the development environment and, therefore, have limited ability to understand events or use tools within Replit. We believe that by training models native to Replit, we can create more powerful AI tools for developers.
A simple example of a Replit-native model takes a session event as input and returns a well-defined response. We set out to identify a scenario where we could develop a model that could also become a useful tool for our current developers and settled on code repair. Developers spend a significant fraction of their time fixing bugs in software. In 2018, when Microsoft released “A Common Protocol for Languages,” Replit began supporting the Language Server Protocol. Since then, the LSP has helped millions using Replit to find errors in their code. This puts LSP diagnostics among our most common events, with hundreds of millions per day. However, while the LSP identifies errors, it can only provide fixes in limited cases. In fact, only 10% of LSP diagnostic messages in Python projects on Replit have associated fixes. Given the abundance of training data, repairing code errors using LSP diagnostics is therefore the ideal setting to build our first Replit-native AI model.
Methodology
Data
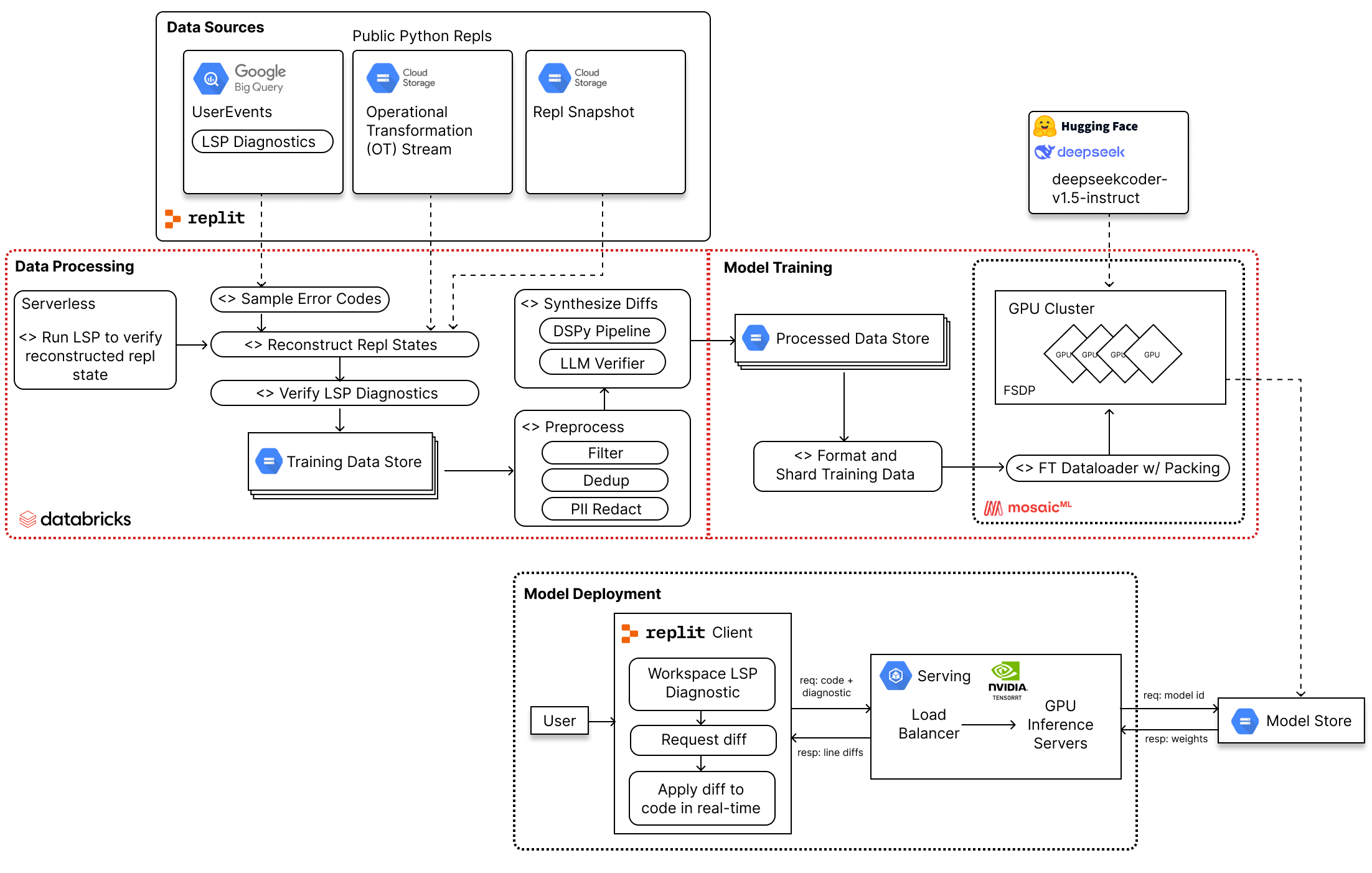
Data sources: OTs, events, and Repl snapshots
A Replit session is a stream of data across multiple modalities. To support multiplayer features, Replit represents code as a sequence of Operational Transformations (OTs). This representation provides an edit-by-edit history of all the changes made to a file and allows us to “play back” a project’s state. A regular snapshot of each project’s most recent state allows us to assert the replay’s correctness.
OT data is merged with session events into a single timeline. Here, we work with LSP diagnostics, but many other events are recorded, including CodeMirror actions (selection, scrolling), package installation, code execution, and shell commands. Windows of this timeline represent tasks the user is performing: implementing a feature, reading and trying to understand a function, fixing a bug or runtime error, etc.
Data pipeline
The goal of our data pipeline is to produce a dataset of (code, diagnostic) pairs. We first recreate the filesystem of a project at the time of the diagnostic, then use LLMs to generate and verify synthetic diffs.
We log all LSP diagnostics from user sessions in BigQuery. The data looks like this:

We exclude:
- diagnostics with associated CodeActions (deterministic solutions provided by the LSP server) since we will always use the CodeAction at inference
- stylistic rules, like ruff[E501] Line too long and ruff[I001] Unsorted imports
- private and non-Python projects
Using OTs, we reconstruct the repl filesystem corresponding to the LSP diagnostic timestamp. As a sanity check, we assert that we can reconstruct the most recent Repl filesystem and match a copy stored in GCS. We also run Ruff and Pyright from our pyright-extended meta-LSP and assert that the expected set of diagnostics is reproduced. LSP executables need to be pointed to a filesystem directory, and in a Spark environment dynamically persisting strings is challenging. For this reason, diagnostics were verified with a serverless lambda that scales up in bursts.
We targeted a dataset of 100k examples but designed a pipeline ready to scale up at least another order of magnitude. As such, we implemented our pipeline with PySpark on Databricks to scale up compute as needed.
Line diff synthesis, distillation, and verification
We synthesize diffs using large pre-trained code LLMs with a few-shot prompt pipeline implemented with DSPy.
We chose numbered Line Diffs as our target format based on (1) the finding in OctoPack that Line Diff formatting leads to higher 0-shot fix performance and (2) our latency requirement that the generated sequence should be as short as possible. We compared Line Diffs with the Unified Diff format and found that line numbers were hallucinated in the Unified Diff both with and without line numbers in the input. Furthermore, Unified Diffs would have a higher decoding cost.
We distill a model from synthesized diffs because fixed errors taken directly from user data are noisier than synthesized diffs. We found that a well-defined synthetic pipeline resulted in more accurate diffs with less variance in the output space when compared to diffs from users.
Compared to synthesizing both the error state and the diff, starting from real error states and synthesizing only the diff is less prone to mode collapse, since the input feature and diff distributions are drawn from the real world. We did not detect mode collapse in our audit of the generated data and recommend synthesizing data starting from real-world states over end-to-end synthesis of samples.
After synthesis, we verify that generated diffs are correctly formatted and applicable. We use regular expressions to extract the line diffs and filter out all other text and incomplete/malformed line diffs. We also apply the generated numbered line diffs to the code file with line numbers to ensure that they can be correctly and unambiguously applied, eliminating samples that cannot be applied due to incorrect line numbers or hallucinated content. Lastly, we increase the proportion of correct diffs to incorrect diffs by prompting an LLM to filter out incorrect diffs, inspired by
Supervised finetuning
Since the distribution of fixed code matches the training distribution of large code LLMs, we hypothesize that the information required to repair LSP diagnostic errors is already contained in the model’s parameters. However, it is difficult to elicit the correct distribution of responses, and to get generalist SOTA LLMs to return a consistently formatted response.
Therefore, we frame code repair as a supervised finetuning problem. Given an LSP error, the line throwing this error, and the code file contents, we finetune a pre-trained code LLM to predict an output line diff. This matches the model’s outputs to the desired inference distribution.
Data format and input/output scheme
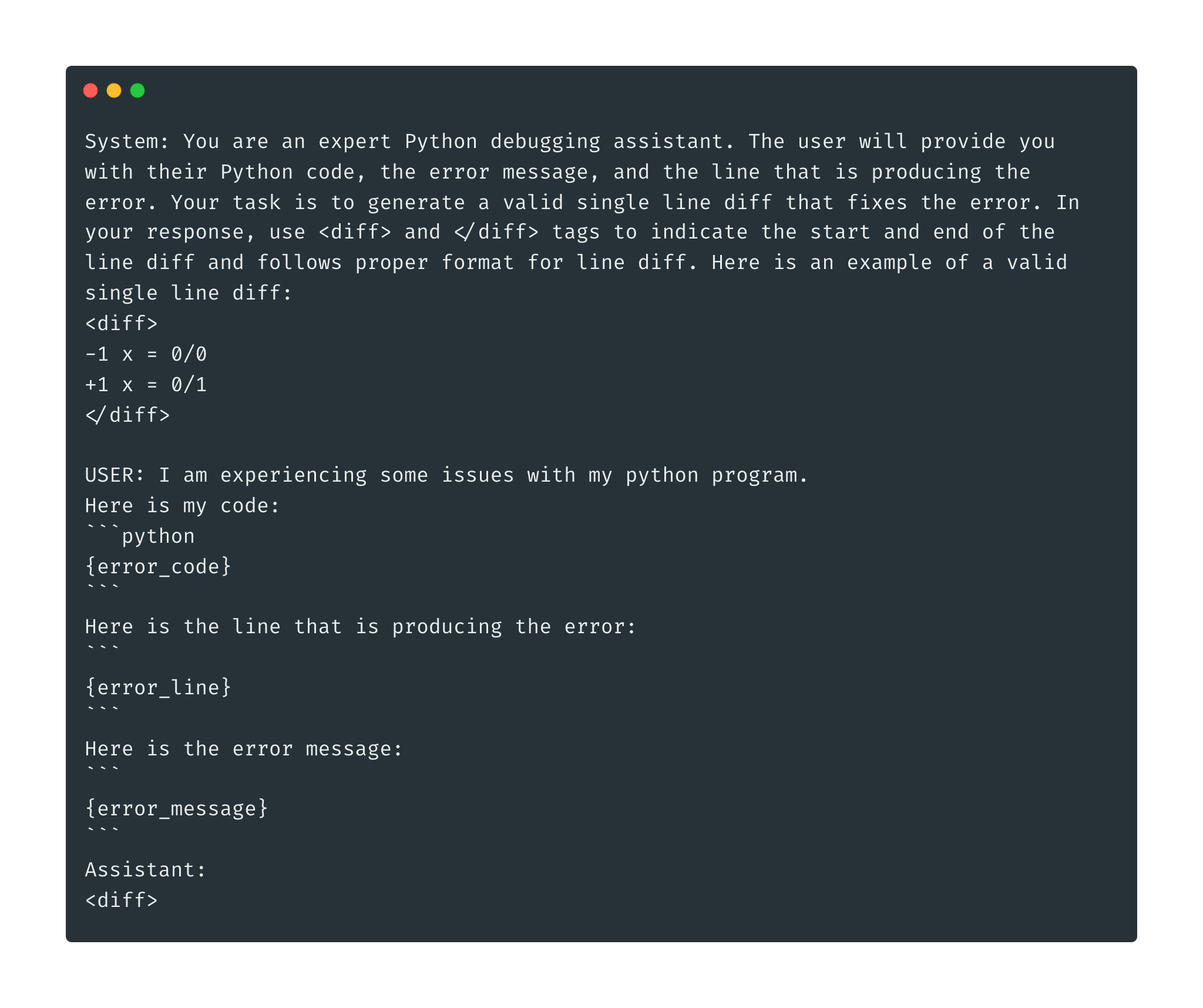
In contrast to the usual instruction finetuning used to finetune code models, we did not use natural language instructions for our code repair model. Instead, inspired by function calling and other approaches to tool usage, we templated data from our IDE into a consistent schema delineated by angle-bracketed sentinel tokens.
Although the base model was trained to follow natural language instructions, we benefit from teaching the model to follow this schema:
- We found that responses are more consistently generated and formatted and, therefore, easier to parse.
- This approach is compatible with and can be extended in future efforts to model Replit sessions as a sequence of events and outputs. For example, we can add sentinel tokens like
<run_command>and<exec_output>to indicate a command that should be run and the execution output after running the Repl respectively.
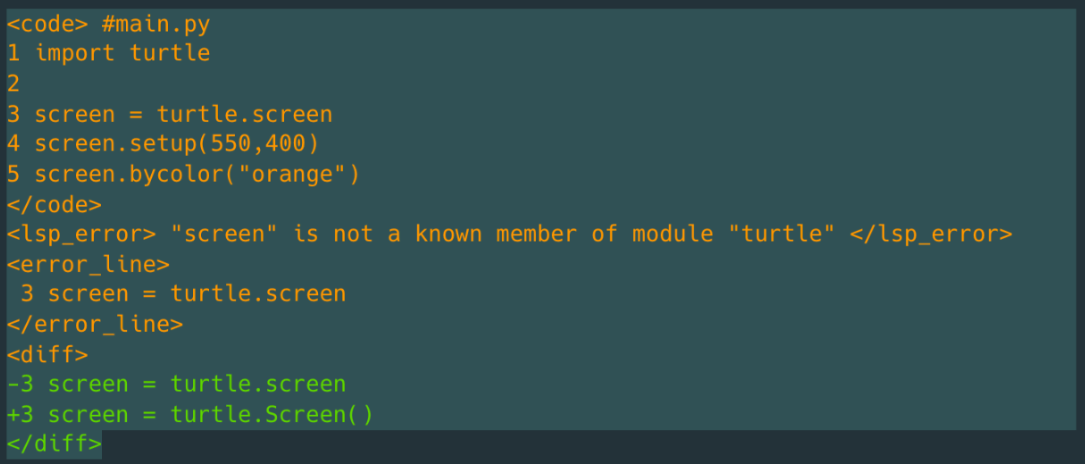
Our rationale for choosing this format is as follows:
- Following OctoPack, we add line numbers to the input code, LSP error line, and output line diffs. Line numbers (1) guarantee the non-ambiguous application of diffs in cases where the same line of code is present in multiple places in the file and (2) empirically boost response quality in our experiments and ablations.
- We follow the base LLM's data format to keep code formatting as close as possible to the model’s training distribution. Therefore, following DeepSeek-Coder, we kept the file name above the file content and did not introduce additional metadata used by other code models, such as a language tag.
- We considered modifying the vocabulary and, consequently, the architecture/dimensions of the base model to have dedicated special tokens for each sentinel token in our schema. However, we decided this was not necessary based on how finetuning performed without this surgery and because the improvement to decoding latency would have been marginal. Our model performed well with each sentinel token mapped to 3-5 tokens from the base model’s tokenizer.
- The flexible output space supports single-line edits, single-line addition/removal, and complex multi-line changes. The output space will dependably match the examples provided in the finetuning dataset, so it can be expanded or constrained by the use case.
Model Training
Base model
We finetuned starting from an open-weights 7B model trained on code. We chose the model size of 7B to balance model capabilities with our constraints of inference latency and cost. We experimented with base and instruction-tuned models from the Starcoder2 and DeepSeek-Coder families and ultimately settled on DeepSeek-Coder-Instruct-v1.5 based on performance.
We downloaded the base model weights from HuggingFace and patched the model architecture to use the Flash Attention v2 Triton kernel.
Infrastructure and distributed training
For training, we used a fork of MosaicML’s LLM Foundry from the v0.5.0 tag with Composer. We trained on the MosaicML platform with a single node of 8 H100s per experiment. We used FSDP with the default Full Shard strategy, and activation checkpointing.
Optimization and hyperparameters
For optimization, we use the Decoupled AdamW optimizer and Cosine Annealing with Warmup as our learning rate scheduler. We set an initial learning rate of 1e-5 and decayed to 0.01x (i.e. alpha_f=0.01), with a warmup of 100 batches, beta_1=0.9, beta_2=0.99, epsilon=1e-8 with no weight decay, and a batch size of 16. Training for 4 epochs gave the best experimental performance, consistent with previous work on pretraining where 4 epochs are considered optimal for smaller, high-quality datasets. We use norm-based Gradient Clipping with a clipping threshold of 1.0. All training was in mixed precision with BF16.
We use a packing ratio of 6.0 for Bin Packing of sequences as implemented in LLM Foundry. This is obtained by a script available in LLM Foundry that profiles packing.
Evaluations
The automated program repair literature has a rich family of evaluation datasets, spanning various programming languages. However, many of these datasets have been shown to be leaked in the pre-training corpus of large-language models for code, making them unsuitable for the evaluation of SOTA LLMs. Furthermore, these evaluation datasets are often curated from professional/well-maintained repositories (e.g. filtered by stars on GitHub), thereby acting as a weak proxy to measure the performance of program repair models on real-world program repair tasks for users of diverse skill levels. To solve these issues, we conduct a two-part evaluation of our model.
Leetcode repair eval
To measure our model's performance on public benchmarks, we select DebugBench, owing to its relative recency, error subtyping, and open-source pipeline. We select a subset of problems from the categories of syntactic and reference errors, as solving these errors can be assisted by LSP diagnostics. For each selected problem, we attach the associated diagnostic from either Ruff or Pyright.
The following is a sample evaluation instance from the dataset:
from typing import List
class Solution:
def lexicographicallySmallestArray(self, nums: List[int], limit: int) -> List[int]:
n = len(nums)
a = sorted(zip(nums, range(n)))
ans = [0] * n
i = 0
while i < n:
st = i
i += 1
while i < n and a[i][0] - a[i - 1][0] <= limit:
i += 1
sub = a[st:i]
sub_idx = sorted(idx for _, idx in sub)
for j, (x, _) in zip(sub_idx, sub):
ans[j] = x
return self.postprocess(ans) #buggy codeThe associated LSP Diagnostic is:
# LSP diagnostics
Error Message: Cannot access member "postprocess" for type "Solution*" Member "postprocess" is unknown'
Error line: return self.postprocess(ans)The fixed solution is:
from typing import List
class Solution:
def lexicographicallySmallestArray(self, nums: List[int], limit: int) -> List[int]:
n = len(nums)
a = sorted(zip(nums, range(n)))
ans = [0] * n
i = 0
while i < n:
st = i
i += 1
while i < n and a[i][0] - a[i - 1][0] <= limit:
i += 1
sub = a[st:i]
sub_idx = sorted(idx for _, idx in sub)
for j, (x, _) in zip(sub_idx, sub):
ans[j] = x
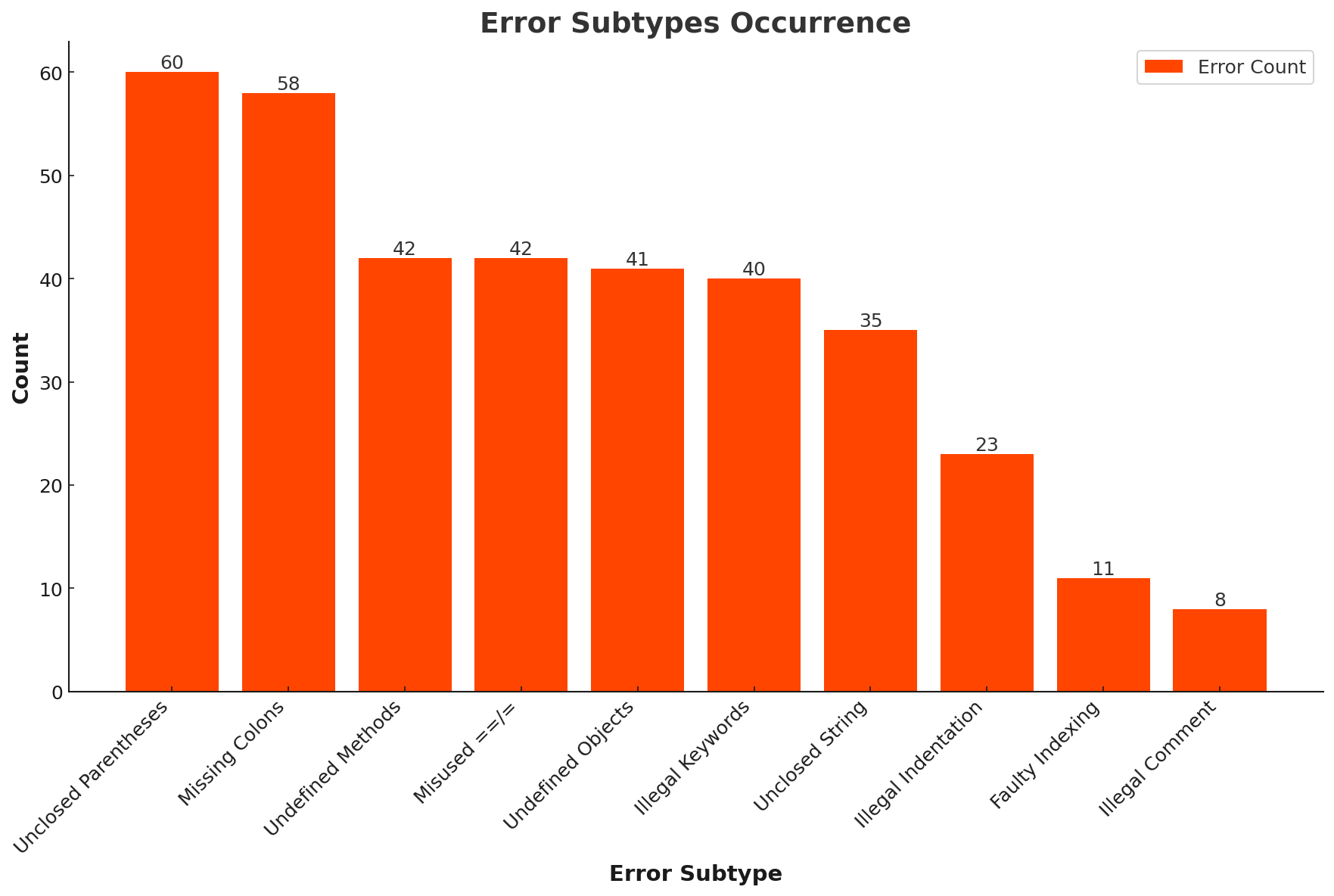
return ans #fixed codeMore recently, LivecodeBench has shown that open large language models struggle when evaluated against recent Leetcode problems. Therefore, in order to strengthen our evaluation, we select recent problems (after the base model’s data cutoff date) from Leetcode competitions as proposed in LiveCodeBench and use the synthetic bug injection pipeline proposed in DebugBench to create additional evaluation instances for the test set. The final distribution of subtypes of problems in our dataset is included in the Appendix and consists of 360 samples.
Replit repair eval
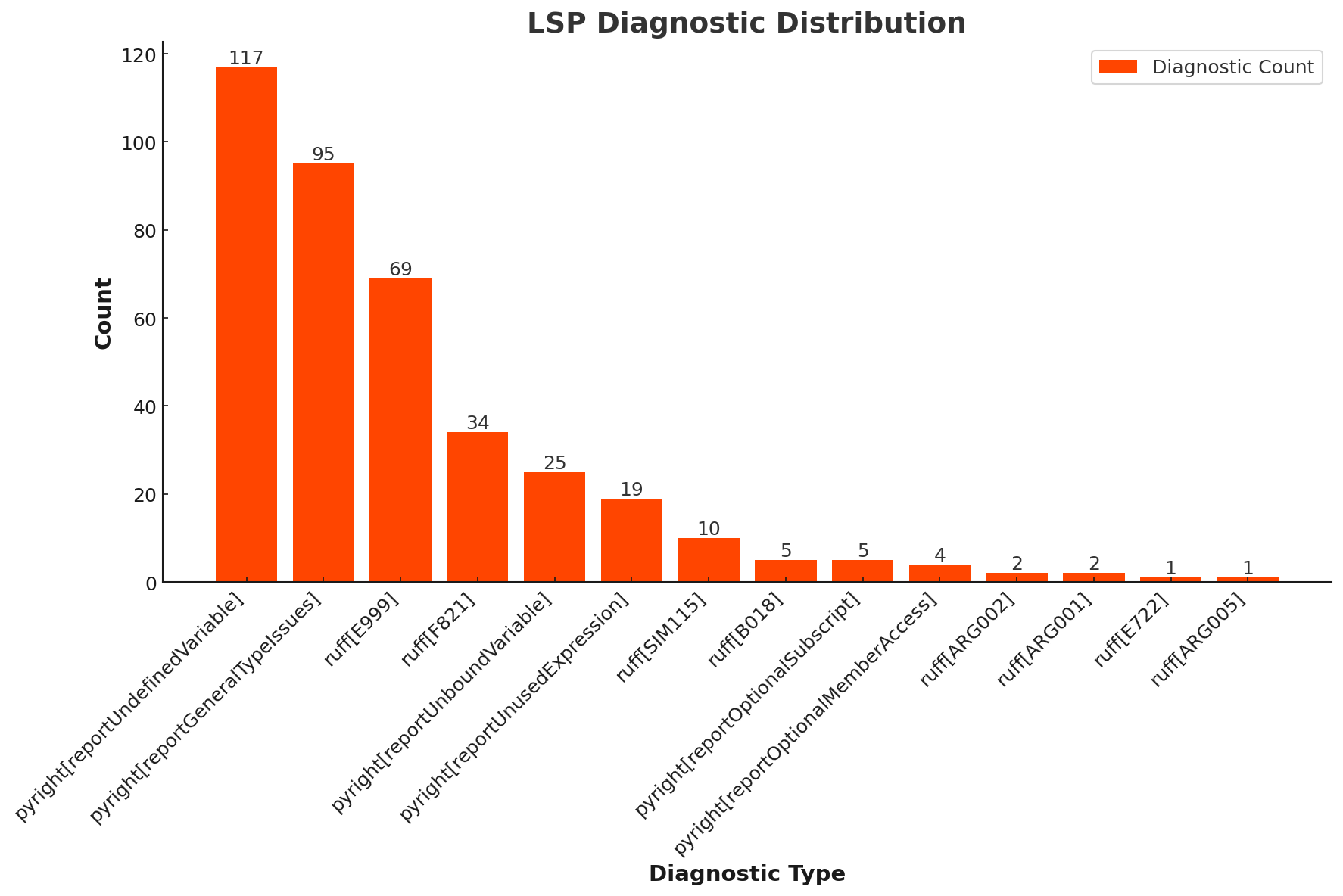
To test the model in our inference setting–that is to say, fixing LSP diagnostics for users while they are writing code on Replit–we needed to create a completely new benchmark. We followed the procedure outlined in Data to sample held-out (code, diagnostic) pairs from each diagnostic type that the model was trained to repair, removing low-quality code when necessary (e.g., .py files containing only natural language). We sample at the Repl level and deduplicate (following the procedure recommended in StarCoder) to ensure no train-test leakage. To create the repaired code, we follow a two-step approach: we first use a SOTA LLM to create a fix for the (code, diagnostic) pair, and a human annotator verifies that the solution is correct. If it isn't the annotator provides a correct fix. The final distribution of LSP diagnostic types in our dataset is included in the Appendix and consists of 389 samples.
Metrics
We measure performance using both functional correctness and exact match metrics.
Functional Correctness: Functional correctness measures the functional equivalence of target code C against the fixed code C’ produced by the application of a predicted line diff to the input code. This metric requires the code to be in an executable state and requires test cases for evaluation. Therefore this metric is limited to the Leetcode repair eval, where solutions are submitted to the platform for evaluation.
Exact Match: Exact match compares the target code C against the fixed code C’ produced by the application of a predicted line diff to the input code. We consider two types of exact matches:
- AST match: We compare the abstract syntax tree (AST) representation of
C’against that ofC. - AST match string fallback: There are several cases where the source code cannot be parsed into a valid AST. However, the fix proposed by the model is still valid, therefore we consider a fix to be acceptable if either the AST or the string representation of
C’matchesC.
Limitation: The exact match metric is a lower bound to functional correctness. However, it is not always feasible to generate tests of functional correctness, so following prior work such as CrossCodeEval, we use exact code match.
Baselines
We compare our model against the following SOTA LLM baselines:
- Models available via API: We use the most recent releases of GPT-4-Turbo (gpt-4-0125-preview), GPT-3.5-Turbo (gpt-3.5-turbo-0125), Claude-3-Opus (claude-3-opus-20240229) and Claude-3-Haiku (claude-3-haiku-20240307). The models are accessed via their APIs.
- Open-source models: We compare the performance of our finetuned model against the base model it was initialized from, DeepSeek-Coder-Instruct-v1.5. This model also has the strongest finetuning performance among the 7B parameter models that we tested. We use the publicly available checkpoint.
Inference configuration
- Few-shot example choice: For each evaluation sample of an error type, the few-shot evaluation examples are chosen randomly from the training dataset by matching the error code.
- Prompt structure: We follow the recommended prompting strategies for large language models. Additional details about the prompt structure can be found in Appendix A.
- Inference hyperparameters: We set the maximum number of output tokens to be the maximum context size of the model, use a temperature of 0.1, and set
top_p=0.95andtop_k=50for nucleus sampling, wherever applicable. - Pass@1: We evaluate the performance of all models in a single pass setting, mimicking their use in a real-world deployment paradigm.
Results
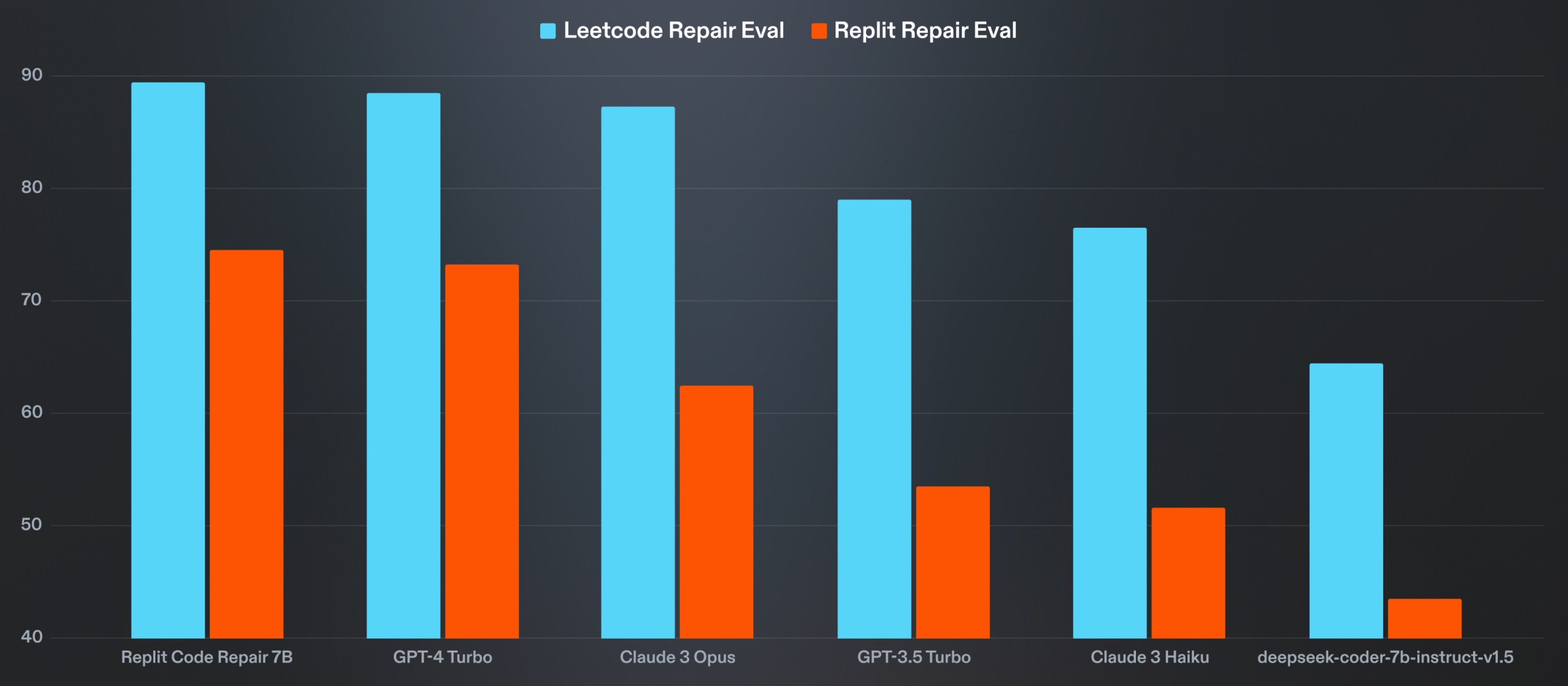
Replit Code Repair 7B is competitive with models much larger on both evaluation benchmarks. The overall performance of models on our real-world eval remains low when compared to the Leetcode repair eval, which demonstrates the importance of evaluating deep learning models on both academic and real-world benchmarks.
Leetcode repair benchmark
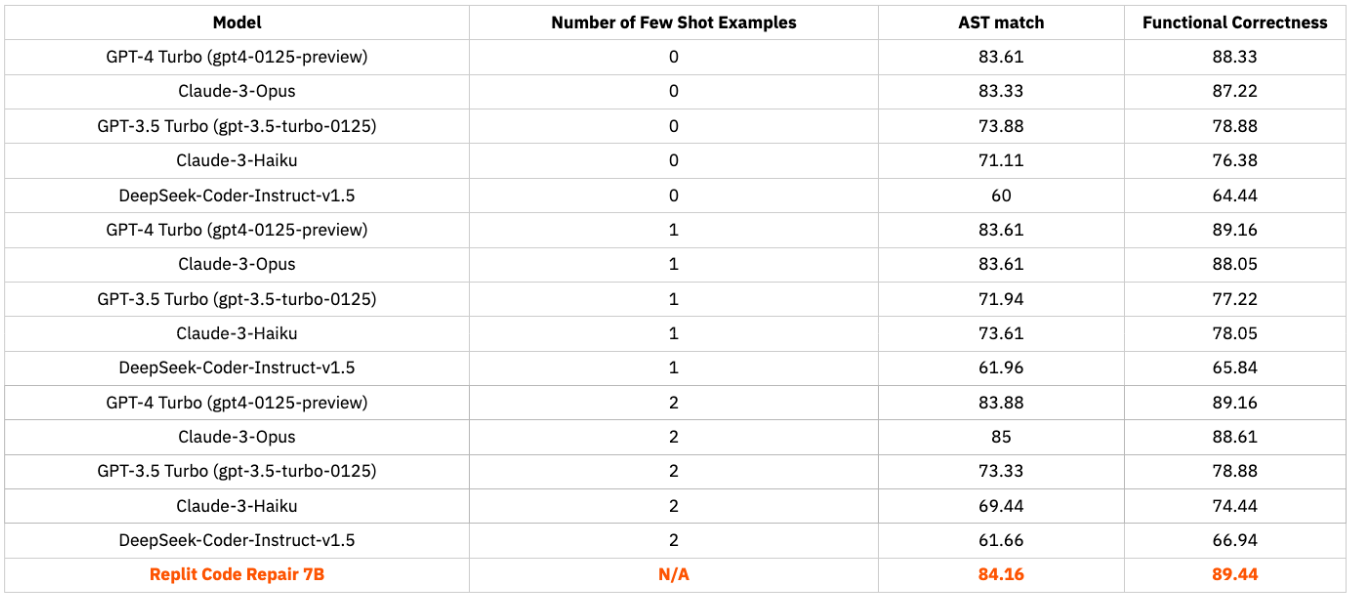
Replit Code Repair 7B is competitive with models that are much larger in size. We note that performance may decrease for smaller models when the number of shots is increased.
Replit repair benchmark
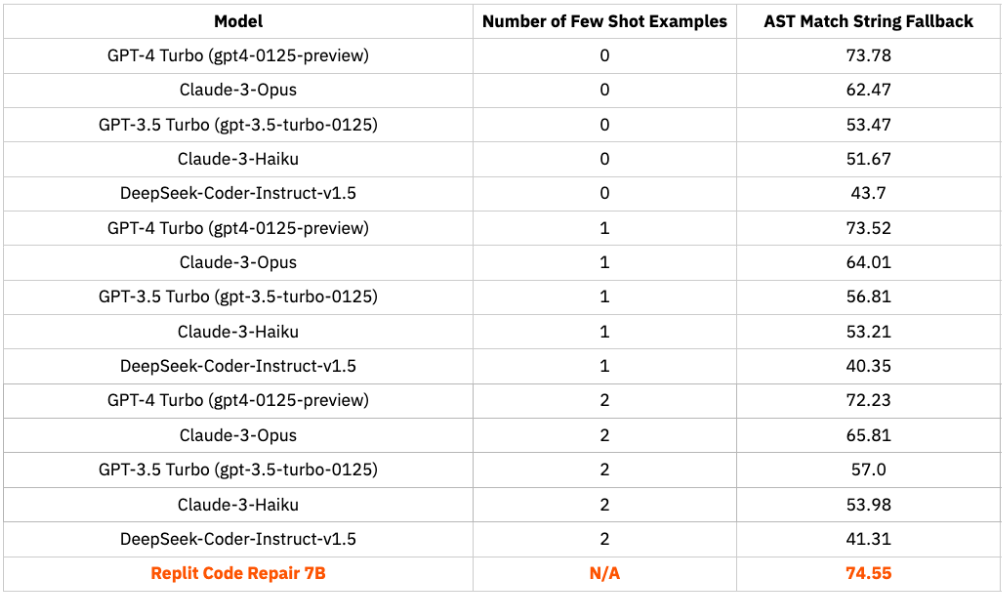
We again find that Replit Code Repair 7B is competitive with larger models. There is a large gap between the performance of Replit Code Repair 7B and other models (except GPT-4 Turbo).
Scaling experiments
Training LLMs is a highly experimental process requiring several iterations to ablate and test hypotheses. Given the low per-experiment cost in our setting, we tested various configurations to develop intuitions about the problem complexity by scaling the dataset and model size and then testing performance as a function of the two.
Data scaling
To test how model performance scales with finetuning dataset size, we finetuned DeepSeek-Coder v1.5 7B Instruct on subsets of 10K, 25K, 50K, and 75K training samples. All subsets were randomly sampled from the same base dataset.
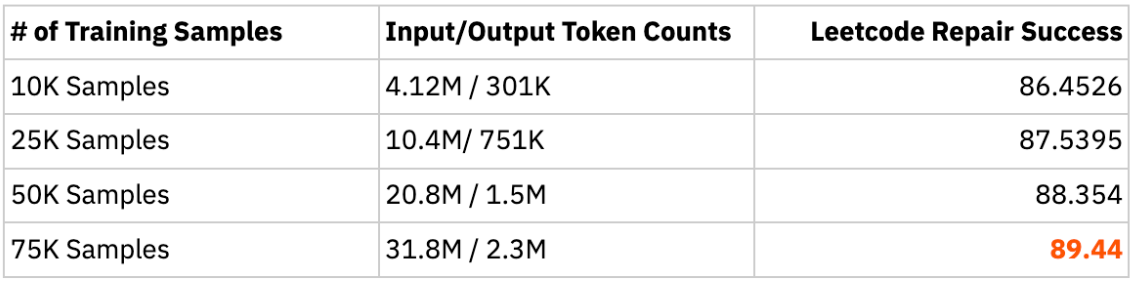
Parameter scaling
To test how model performance scales with model size, we finetuned various backbones from the DeepSeek-Coder v1 Instruct family on a fixed 75k sample dataset. We used v1 as the base model for this experiment because v1.5 is only available at the 7B size.

Related Work
There is a long history of work focused on fixing bugs or vulnerabilities in code [Monperrus 2018].
The strongest traditional approaches applied ground truth templates or operators, written by experts or curated based on datasets of bugs [Ghanbari 2018, Liu 2019].Over time, learning-based approaches gained popularity, which leverage pairs of (broken, fixed) code to expand the distribution of bugs and their fixes. Following the success of neural machine translation (NMT), researchers began to model program repair as translation from buggy to fixed programs [Lutellier 2020, Jiang 2021, Zhu 2021, Ye 2021, Ye 2022]. Due to the poor diversity and quality of synthetic data at the time, NMT approaches required datasets of (broken, fixed) code pulled from open-source repositories, which were often too small to produce significant improvements over traditional approaches.
Break-It-Fix-It introduced a “breaker”, which transforms fixed to broken code, trained in competition with a “fixer” to produce realistic errors. This made it possible to bootstrap a repair model, starting from unrealistic synthetic examples, and iteratively making them more realistic [Yasunaga 2021].
Since [Brown 2020, Kaplan 2020, Chen 2021, Fried 2022], many groups have applied code LLMs to program repair [Berabi 2021, Xia 2023]. In this paradigm, LLMs are trained using self-supervised learning on large datasets, and have impressive 0-shot capabilities to repair programs [Xia 2022, Fan 2022, Mohajer 2023]. To achieve stronger performance with smaller models, several groups have applied full-parameter supervised finetuning and parameter-efficient finetuning methods like LORA to specialize the model to the program repair task [Jin 2023, Silva 2023, Huang 2023]. Recent work has applied more sophisticated prompting strategies or agentic behavior [Bouzenia 2023, Xia 2023, Kong 2024].
Future work
Given these promising results, we are working on several extensions.
The space of fixes for program repair using the LSP is quite large in terms of the complexity of fixes and code context. So we are further curating data and performing experiments for more complex cases such as cross-file edits, improving performance for multi-line edits and supporting the long tail of errors that we see on Replit. Of course, this will be accompanied with scaling our base training dataset given our data scaling experiments.
We are also working to support a larger set of programming languages, and we are eager to find out if we will observe transfer-learning across languages, as we have observed when pretraining code completion models. For this reason, we are putting more work into our evals to capture the wider distribution of LSP errors across the many languages supported by Replit.
Once the model is in production, we will experiment with post-training methods like DPO leveraging user data collected by the Replit platform, such as which code fixes are accepted and rejected.
Acknowledgements
We would like to thank Databricks and the MosaicML team for their support with model training tools and infrastructure. We would also like to thank DeepSeek for open sourcing their DeepSeek-Coder models. Finally we would like to acknowledge Bradley Heilbrun, Jacky Zhao, Brady Madden, Connor Brewster, Ryan Mulligan, and many others at Replit for their help and for building the systems that made this project possible.
Contributors
- Ryan Carelli* worked on experimental design, data sourcing, data pipelines, training and ablations, analysis and evaluation.
- Madhav Singhal* work on on experimental design, data pipelines, synthetic data pipeline design and implementation, training and ablations, analysis and evaluation.
- Gian Segato worked on data sourcing, data generation and compatibility with the LSP, data pipelines, synthetic data pipelines, evaluation data and analysis.
- Vaibhav Kumar worked on data sourcing, evaluation, benchmarks, ablations and analysis.
- Michele Catasta was the Principal Investigator.
*Equal contribution
Citation
@online{replit2024coderepair,
author = {Singhal, M. and Carelli, R. and Segato, G. and Kumar, V. and Catasta, M.},
title = {Building LLMs for Code Repair},
year = {2024},
url = {blog.replit.com/code-repair},
urldate = {2024-04-02}
}Appendix
Distribution of errors in our evaluations
Prompt for 0-shot evals of generalist LLMs
We extend the prompt to include few-shot examples by adding additional user-assistant pairs to the conversations as needed.