At Replit, our mission is to empower the next billion software creators. Yesterday, we strengthened our commitment by announcing that Replit AI is now free for all users. Over the past year, we’ve witnessed the transformative power of building software collaboratively with the power of AI. We believe AI will be part of every software developer’s toolkit and we’re excited to provide Replit AI for free to our 25+ million developer community.
To accompany AI for all, we’re releasing our new code generation language model Replit Code V1.5 3B on Hugging Face. We believe in open source language models – anyone can use it as a foundational model for application-specific fine-tuning without strict limitations on commercial use.
Key Features
- Extensive Permissively Licensed Training Data: Trained on 1 trillion tokens of code from permissively licensed code from the Stack dataset and publicly available dev-oriented content from StackExchange.
- State of the Art Results: Leading HumanEval and Multi-PLe evaluation scores for a 3B code completion model.
- Broad Multi-Language Support: Encompasses Replit's top 30 programming languages with a custom trained 32K vocabulary for high performance and coverage.
- Latest Techniques: Built with all latest techniques such as Grouped Query Attention with Flash Attention Triton Kernels, ALiBi positional embeddings, and more, for low latency and high generation quality. Trained with the latest techniques like LionW optimizer, learning rate cooling down, QKV clipping and more.
- High Quality Curated Training Data: Incorporated specialized code quality filtering heuristics, parsability checking, toxic and profane content removal that lead to higher quality generations.
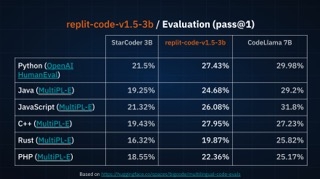
Here's how the model performed against leading benchmarks:
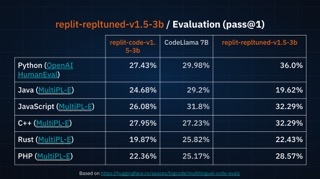
When fine-tuned on public Replit user code, the model outperforms models of much larger size such as CodeLlama7B:
The model is intended to be used by anyone as a foundation for application-specific fine-tuning and is trained specifically for code completion tasks.
How to use Replit V1.5 3B
The model is trained specifically for code completion tasks. You can generate code using the transformers library as follows:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('replit/replit-code-v1_5-3b', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('replit/replit-code-v1_5-3b', trust_remote_code=True)
x = tokenizer.encode('def fibonacci(n): ', return_tensors='pt')
y = model.generate(x, max_length=100, do_sample=True, top_p=0.95, top_k=4, temperature=0.2, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
generated_code = tokenizer.decode(y[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(generated_code)Check out our Hugging Face README for more details on how to use GPUs with optimized the Triton kernel that our model supports.
Experiment with different decoding methods and parameters to get the best results for your use case.
For a deeper dive, check out the guide on training your own LLMs that we published alongside the first iteration of this model. Stay tuned for a technical deepdive from a member of our AI team where we’ll discuss our fine tuning process and challenges along the way.