We mostly think of repls as being full computers in the cloud, and one of the goals of the platform team at Replit is to enable people to build almost anything in replspace. In the past, when a file was stored in a repl, it would only be saved when the editor was opened. This went against our goal and made it impossible to write certain servers that changed files at runtime. This was especially hard for newcomers, because that's the easiest way to persist information. Starting today, Hacker and Teams subscribers will be able to write services that accept file uploads or store data in a local database (think SQLite) or text file, regardless of how the repl was started.
A demo of what it looks like for a server to be able to save its files: https://sqlite.luisreplit.repl.co
A demo of what it looks like for a server to be able to save its files: https://sqlite.luisreplit.repl.co
What is replspace?
replspace is a term we coined up. In operating systems, memory is divided into kernel space and user space. Kernel space is where the kernel executes and provides its services. The kernel can access all of the memory, but the user cannot access the kernel's memory directly. By contrast, user space is all the memory that a user can access without modifying the kernel sources (or creating a kernel module). The term user space has also been used to refer to the programs that are run by users.
This memory separation is important because the kernel manages all hardware resources, providing access control and coordination, and provides abstractions that let programs that run in user space make requests to interact with those resources. The kernel has several interfaces so that the user space programs can communicate with the kernel, the most important one being the system call interface. These use the abstractions laid out by the kernel to ensure that users and programs don't interfere with each other and also iron out differences in the underlying hardware and provide a uniform "view" of the resources available to the machine.
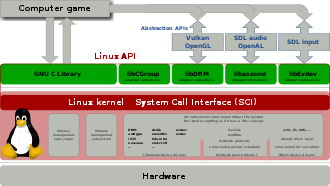
What is replspace, then? By analogy, replspace is all the memory that users of a repl can access, as well as the programs that can be run. In other words, anything that a user of a repl can do is replspace!
Tell me about the support for saving files now!
We have two ways in which we save users' files: Operational Transformation history logs and btrfs filesystem snapshots. Text files that are opened from the editor are saved with the former, which also provides nice collaboration capabilities. But non-text, binary files are not well supported by Operational Transformations, so we rely on saving the whole state of all the files through a feature of the btrfs filesystem in Linux called snapshots.
There are a few tools at our disposal that we can use to know when files changed. The most commonly-used one is a kernel system call named inotify, which lets users "monitor filesystem events" (changes to individual files, individual directories, or to files inside one directory). We use this feature to reload the new contents of the file in the editor after formatting a file, or to know when another user in a multiplayer session created or deleted a file. But this feature is not very scalable: since it can only detect changes in one directory at a time, detecting that any file in a repl changed would be very expensive! So for the longest time, we have had this weird flow of the editor telling the repl about what set of files and directories it cares about, the repl telling the editor that something the editor cared about changed, and then relied on the editor to detect when things change and start a new snapshotting process. This is why a repl that was started as a server was not able to save any files: there was no editor connected to tell the repl to save a new snapshot!
We currently use the Long-Term Support version of Ubuntu Linux. It very recently released version 20.04.3 LTS, which included the 5.11 Linux kernel. This includes lots of very cool features! And buried inside the 5.9 release notes is a small change:
fanotify: report events with names. With these you can now efficiently monitor whole filesystems [...].And efficiently monitoring whole filesystems is exactly what we needed to do in order to know when to save a new snapshot! Now we can stop having that weird repl-editor-repl flow and instead let the repl save a new snapshot every time it detects a new change to any file inside the repl (with a little bit of delay to avoid saving too often, like every time a new letter is typed in a file). The editor is no longer in the picture, so this behavior happens regardless of how the repl is started. Check out a demo repl!
Since repls run in a Linux container, the kernel version that's accessible from the repl has to match the kernel that is used in the machine itself. This means that as a happy side-effect, all repls can now access all the new features unlocked by this upgrade. Note that not all system calls are accessible from replspace (because that would be a security nightmare for us!), but we're still very excited to see all the new things that you will build with these new capabilities. Especially because this upgrade made several things a tiny bit faster, and those things tend to add up.
We're huge proponents of building things that can then be used to build more things, especially for the next generation of programmers and engineers. This has a compounding effect because programmers in turn build things to make people's lives easier. If any of this inspired you to build something cool, let us know! And if you want to help us build the next big thing, we are hiring!