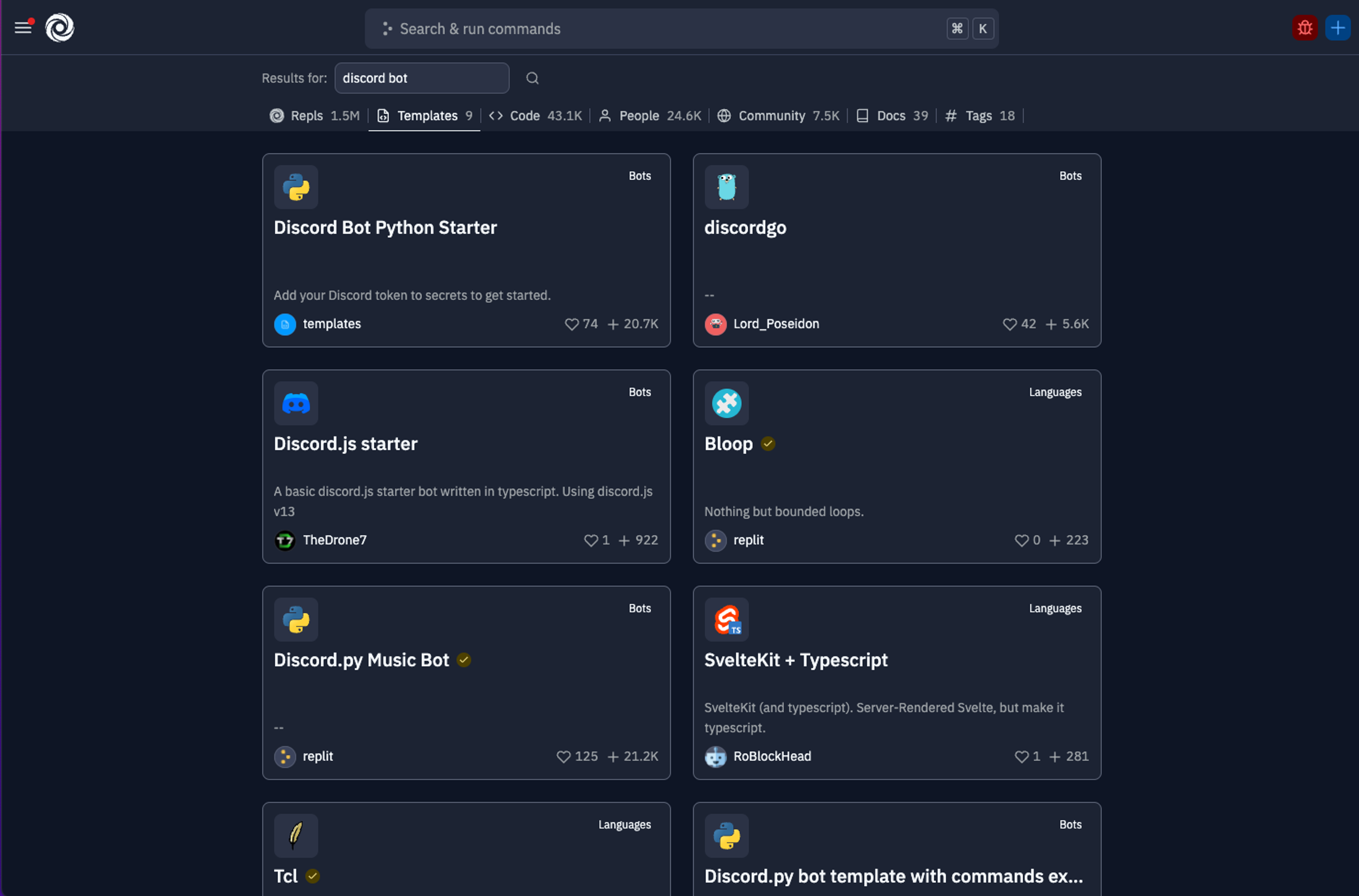


For the past few months, we have been building a Replit-native search engine. It is remarkably powerful, and we are really excited for you all to try it out. We believe that you should be able to find anything on Replit in less than 30 seconds.
This might sound simple, but when you have 100 million+ Repls, it becomes complicated. :)
When you search for something on Replit today, you'll see a page with relevant results from the following categories:
- Repls
- Templates
- Code (yes, code)
- Users
- Community content (published repls, posts)
- Our docs
- Community tags
Why we built it
We think that being able to search for stuff is important. Searching can help you find inspiration, discover other users, and even learn how to code.
Prior to this update, there was no effective way for users to find anything on Replit. You could only search through the names of Repls that you owned. Even then, you had to type the exact string match to get any results.
We have known for a while that the search experience needed to be updated, but for much of last year we focused on more critical projects. (Workspace stability, abuse, etc.)
Aside from our team's general dissatisfaction, there were a few other signals that prompted us to fix the search experience:
- qualitatively, people complained about the lack of functionality in surveys and interviews.
- quantitatively, 80%~ of users that navigated to search ended up dropping off entirely. They weren't able to find what they were looking for. Retention for this feature was also significantly lower than other features.
In building this, we hope to give everyone tools for the self-led discovery of all different types of content on Replit.
How we built it
A search engine has a few different components:
- A web frontend where users type their queries and see results
- A server backend that receives requests from the frontend and serves responses
- The actual search engine that indexes documents and executes search queries
- Data pipelines for creating and updating search indexes
The first two were relatively straightforward. We built the search page like we build every other page on Replit: in Typescript, with a Next.js (React) frontend and an Express backend, with GraphQL as the API layer in between.
The other components were a little more complicated, since we haven't done anything like this at scale before.
A few other small search features on the site such as the community search box were built with the Sphinx library. This was simple to set up at the time with some custom infrastructure to support indexing and executing queries. However, this setup hasn't aged well, and we weren't comfortable expanding it to vastly larger datasets.
After looking through our options, we settled on Elasticsearch because of its stability, supporting libraries for big data ingestion, and the large community that has battle-tested it in production setups over the years.
For the data pipelines we use Apache Spark. These are high-throughput jobs that run on clusters of many machines at once. The details of how these jobs work is worth a post on its own, but broadly speaking they take data from other locations (the BigQuery data warehouse, Google Cloud Storage, etc), process them into search documents, and bulk upload to the Elasticsearch cluster.
We're working on scaling these big data jobs even further. For example, our code search supports searching through the contents of published repls. In the future, we'll expand this to every file in every repl. You'll be able to find even more working code results and sample code to learn from.
What's next?
On March 31st, we released search to 100% of users.
If you helped with any early prototypes, participated in any user interviews, or were a part of the explorer beta, we want to say thank you! We could not have made it this far without your help.
If you'd like to leave feedback on the new search experience, please leave a comment on this Repl. We're open to any and all types of feedback.
If this project seems interesting to you, consider checking out our careers page. :)


