
Why did we build it?
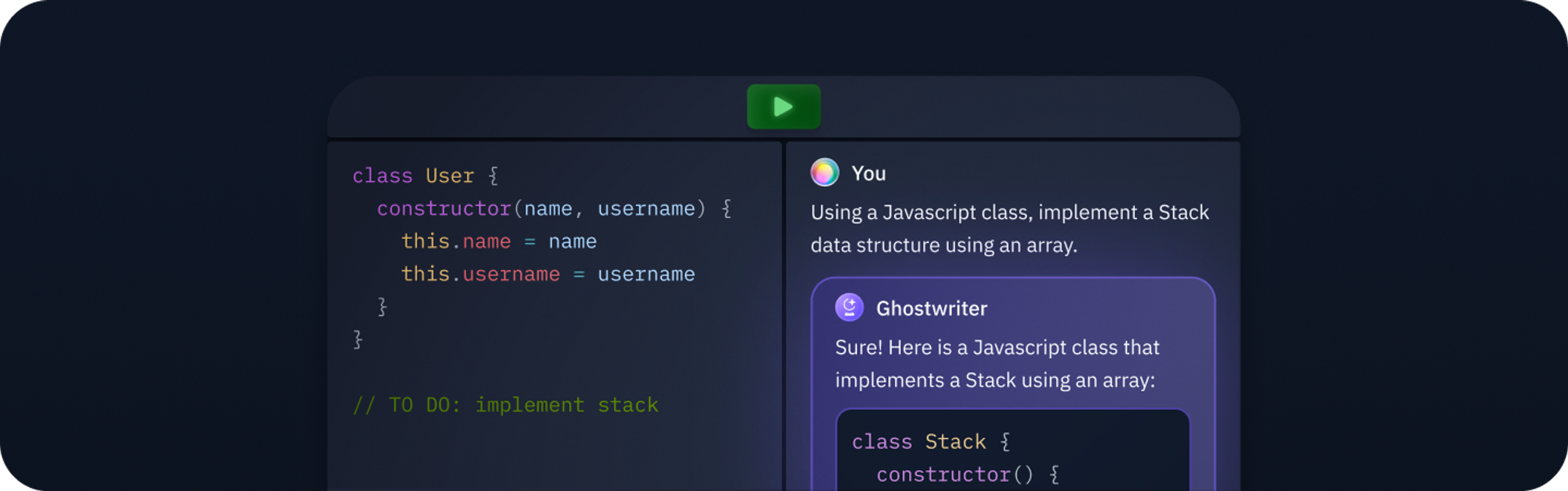
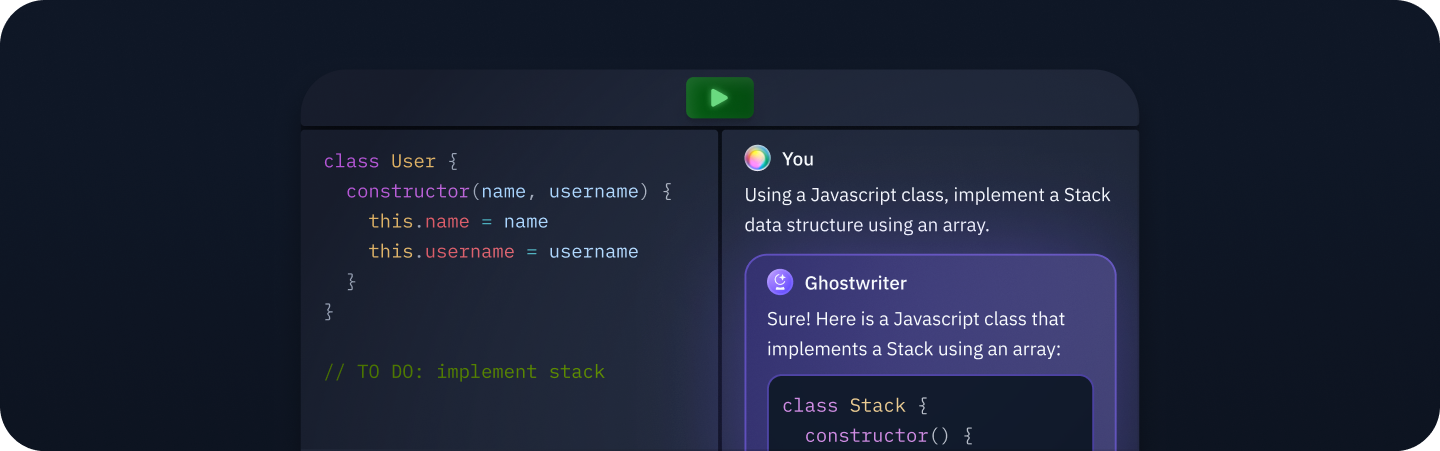
At Replit, we want to give people the most powerful programming environment, and what better way is there than giving people access to a pair programmer directly in their IDE? Enter Ghostwriter Chat.
Gone are the days where you had to search Stack Overflow for an obscure error message or visit the docs of your favorite package for the millionth time because you forgot what that one argument was called. Interacting with Ghostwriter should be as easy as interacting with a team member, and it is. Since Ghostwriter Chat can have access to your repl file and context, Ghostwriter can help answer questions about your program without copying and pasting entire code blocks.
We started working on Ghostwriter Chat during our Hackweek in January, and we wanted to be the first to market with an LLM chat application native to your editor. From start to finish, we shipped the product in ~6-8 weeks
Large Language Models
Large language models (LLMs) are the underlying technology powering Ghostwriter Chat. The recent advancements in the field make these language models very good at answering programming questions.
A typical chat request goes through the following steps:
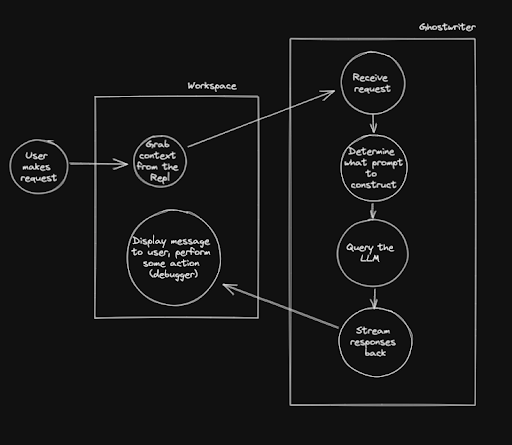
The LLM is the contributor to the largest amount of latency in this process, so streaming the results back instead of waiting for the entire completion is important. If we do not stream, a user will have to wait multiple seconds for the language model to generate all tokens. Streaming gives us the ability to have sub 500 milliseconds from the time a request is sent, to when the user starts seeing a response displayed.
Generic Prompt Construction
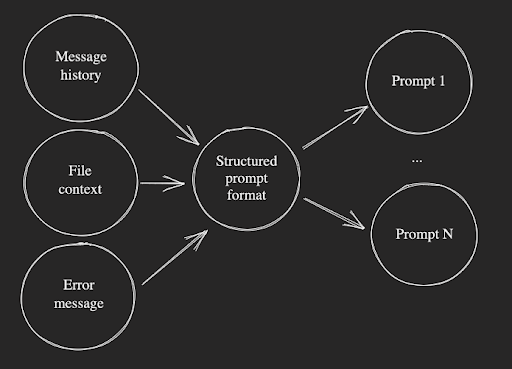
When working with LLMs, you need to invest a lot of thought into how you construct the prompt that you feed in. A carefully constructed prompt with sufficient context, can yield a very detailed response while a simple, basic prompt can yield something that is not very helpful.
For Ghostwriter to be able to help you answer your questions, it needs to have knowledge of the ever changing environment of your repl and your chat history. To succeed, we needed a way to take varying information from different sources, choose what to include and exclude, and convert it to any number of prompt formats to support any number of models and APIs.
Ghostwriter Debugger
For Ghostwriter Debugger to work, we also need to support the many different ways programs display and throw errors. For example, a running web server can throw errors without pausing execution and continue to output logs, but a script is going to immediately stop with the last output being an error message.
Ghostwriter Chat Debugger
Getting Around Token Limits
Unfortunately, language models have a token limit on the input and output tokens. This makes it impossible for us to include all of your repl context, additional external context, and your entire chat history. To get around this, we use some heuristics we feel is a good balance to allow chat to have access to what is most important.
Limit the chat history we send to the model
Assuming that the most recent messages are the most important during a conversation, removing old messages is a good way to keep in these context limits.
Set a cap on how large a message can be
A message to Ghostwriter counts as part of the prompt and the total limit, so we set a cap at 500 characters to allow more room for other parts of the prompt (chat history, larger responses, file context). If most users want to reference code they have written in a message and we are including file context already, you can get better results by asking Ghostwriter about the code itself instead of copying and pasting in each message.
Be smart about what is good context and what is bad context
For example, a small Repl might only have a hundred or so lines of code and two files. That is very easy to keep the full context of the repl when interacting with Ghostwriter. But what about larger and more complex Repls? It's impossible to send the entire project to a language model, let alone the entire project and your chat history.
Some files are less relevant than others. A python project might have a directory called .venv/, some linter files, some pytest configurations, a .gitignore file, and a bunch of yaml CI build files. Are these really going to help make Ghostwriter give users better programming advice? Most likely not. The most relevant files would be things like main.py and other source code.
When programming, an example workflow is to think about what you want to do, write some code, forget the best way to do something, look it up, and repeat. This isnt always the case, but if you are focusing programming and you are stuck, it's almost on the immediate task at hand. We can take advantage of this common flow, by assuming that the most important files for Ghostwriter to know about are the files you are currently working on and have recently worked on. Doing so gives Ghostwriter the most context on the task you are doing at hand and enables it to truly be your pair programmer.
The Future
Ghostwriter Chat will only get more and more powerful as AI and LLMs become stronger. Token limits will get larger, inference speeds will get faster, which means future versions of Ghostwriter, and other LLM based applications, will only get smarter, better, and faster.
These trends will allow us to unlock more seamless interaction with our IDE, leverage more file context, and allow Ghostwriter to do more complex actions. Ghostwriter will continue to grow and innovate.


