The Problem: Browsers Don't Want to Be Cameras
Here's a deceptively simple product requirement: take a web page with animations, and turn it into a video file.
Sounds easy, right? Open a browser. Record the screen. Export MP4. Ship it.
We tried that. It doesn't work.
The core issue is that browsers are real-time systems. They render frames when they can, skip frames under load, and tie animations to wall-clock time. If your screenshot takes 200ms but your animation expects 16ms frames, you get a stuttery, unwatchable mess. The browser kept rendering at its pace while we captured at ours, and the two never agreed.
We needed something more radical. We needed to make the browser believe time moves only when we say it does.
Why Not Remotion?
Before we go further, a reasonable question: why build this at all? Remotion exists and it's genuinely great. Remotion solves the deterministic rendering problem elegantly: everything is a React component controlled by the library, so it knows exactly what frame you're on and can render any frame in any order. That also unlocks parallel rendering across multiple browser tabs or machines, because frames are independent.
We seriously considered it. But our use case has two specific constraints.
First, Replit's video renderer takes a URL and produces an MP4. The page behind that URL might use framer-motion, plain CSS animations, raw <canvas>, or some obscure confetti library. We don't control what's on the page. We just need to capture it perfectly. Remotion gives you determinism by design, but requires you to build inside its component framework. We needed determinism from the outside, applied to arbitrary web content.
Second, our videos are generated by an AI agent. Constraining the agent to Remotion's component model would mean teaching it one library's idioms instead of letting it use the entire web platform. The less framework surface area the agent has to reason about, the better the output.
So: no special framework. No library buy-in. Just a URL. This meant building the hard thing: making an arbitrary browser environment deterministic after the fact.
Freezing Time: The Virtual Clock
The heart of our video renderer is a JavaScript file (roughly ~1,200 lines at time of writing) that gets injected into every page we capture. Its job is simple and audacious: replace the main time-related APIs in the browser with a fake clock we control.
We replace setTimeout, setInterval, requestAnimationFrame, Date, Date.now(), and performance.now(). In practice, this covers the major JavaScript timing primitives most animation code relies on. The page thinks time is passing normally. In reality, time advances by exactly 1000/fps milliseconds per frame, and only when we tell it to.
This means a 60fps animation that takes 500ms per frame to actually render will still produce a butter-smooth 60fps video. The page never knows the difference. From its perspective, each frame takes exactly 16.67ms, always.
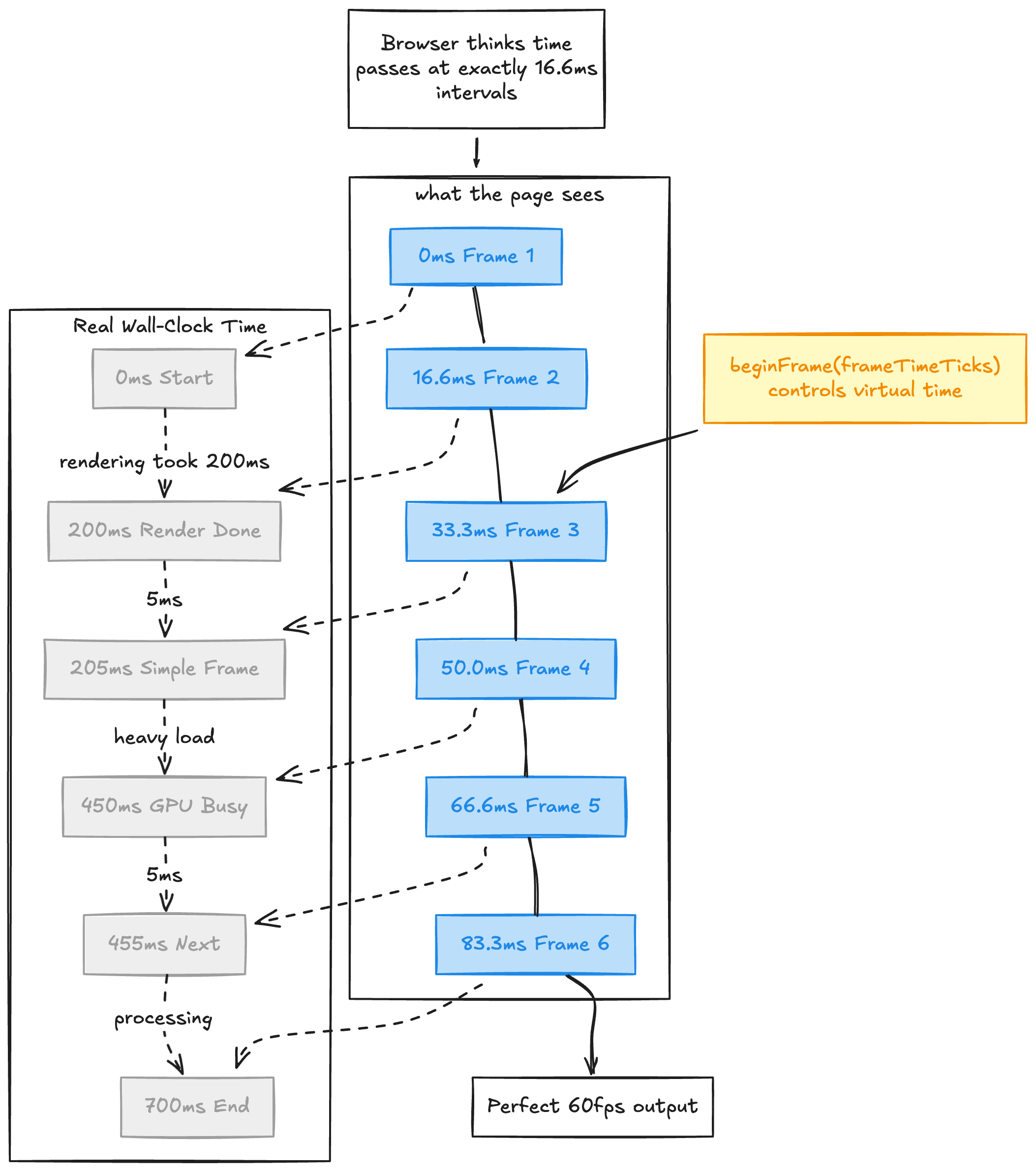
The frame loop looks like this:
nextFrame() {
const loop = async () => {
await seekCSSAnimations(currentTime); // sync CSS
await seekMedias(); // sync videos
currentTime += frameInterval; // tick the clock
callIntervalCallbacks(currentTime); // fire setInterval
callTimeoutCallbacks(currentTime); // fire setTimeout
callRAFCallbacks(currentTime); // fire rAF
await captureFrame(); // screenshot
loop(); // next frame
};
loop();
}Advance clock. Fire callbacks. Capture. Repeat. Every frame is deterministic, every time.
The Compositor Warmup Problem (Or: Why We Render Invisible Frames)
We discovered a fun bug during development: if there's any delay between loading the page and starting the recording (we fire a hook at start and end times to only record the portion we need), Chrome's compositor gets into a bad state.
The root cause? We drive Chrome's rendering loop frame-by-frame rather than letting it render freely. If no frames are issued for a while, internal buffers go stale. The fix is a warmup loop that continuously issues "skip frames" at ~30fps while waiting for the page to signal it's ready to record:
startWarmup() {
const warmupFrame = async () => {
if (startFlag) { stopWarmup(); return; }
await skipFrame();
warmupTimerId = setTimeout(warmupFrame, 33);
};
warmupFrame();
}We render dozens of frames that nobody will ever see, just to keep Chrome's compositor from going stale.
The <video> Element Saga: A Five-Layer Workaround
Here's where things get truly wild. In headless environments, relying on the browser's native <video> playback path is fragile and often non-deterministic for our use case. Different codec/container combinations behave differently, and we still need frame-perfect seeking tied to virtual time.
Our solution is a Rube Goldberg machine of video processing that would make any sane engineer weep:
- Intercept: A
MutationObserverwatches the DOM for<video>elements - Preprocess server-side: When a video source is detected, the page posts to an internal endpoint (/__video_preprocess) that Puppeteer intercepts. We then run FFmpeg on the server and transcode to fragmented MP4 (
-movflags frag_keyframe+empty_moov+default_base_moof) - Demux in-browser: The preprocessed video bytes are returned to the page, where mp4box.js demuxes them into encoded video chunks
- Decode with WebCodecs (native-first, polyfill fallback): We ask for a decoder via
LibAVWebCodecs.getVideoDecoder(...), which prefers native WebCodecs when available and falls back to a WASM-based libav.js polyfill when compatible - Render to canvas: The original
<video>element is visually replaced with a<canvas>that paints decoded frames synchronized to our virtual clock
The fragmented MP4 format is critical here: it lets mp4box.js begin parsing incrementally without needing to seek to the end of the file first. Decoding uses a 10-frame lookahead window to keep latency down without blowing up memory:
const DECODE_LOOKAHEAD = 10;
feedChunksUpTo(targetIndex) {
const end = Math.min(targetIndex, this._chunks.length - 1);
for (let i = this._fedUpTo + 1; i <= end; i++) {
this.decoder.decode(chunk);
}
this._fedUpTo = Math.max(this._fedUpTo, end);
}Audio: Wiretapping the Web Audio API
You can't reliably capture audio output from a headless browser. So we don't try to capture speaker output. Instead, we spy on playback intent.
We monkey-patch key Web Audio API and HTMLMediaElement entry points to intercept audio metadata at the source, before it ever reaches a speaker path:
// 1. Patch fetch() to track ArrayBuffer -> URL mappings
// 2. Patch XMLHttpRequest for arraybuffer responses
// 3. Patch decodeAudioData to map AudioBuffer -> source URL
// 4. Patch AudioNode.connect to build the connection graph
// 5. Patch AudioBufferSourceNode.start to detect playback timing
// 6. Patch HTMLAudioElement.prototype.play to catch new Audio(url).play()When the page plays a sound, we now know: which audio file, when it started, how loud it should be (by walking the GainNode graph), and whether it loops.
This approach covers the most common audio paths and is designed to work across Howler.js (Gemini loves using this for some reason), Tone.js, raw Web Audio, and plain <audio> usage patterns. There are known gaps — programmatically generated audio via OscillatorNode, audio from <video> elements, and AudioWorkletNode processing aren't captured by this approach, since they don't expose a fetchable source URL. The AudioNode.connect patch acts as a partial safety net since all audio nodes must route through the graph, but fully synthetic audio remains a limitation.
Then we download the original audio files server-side, and in a second FFmpeg pass, we mix them all together with proper timing, volume, and fade effects using a filter chain:
Per track: [N] atrim -> aloop -> adelay -> volume -> afade -> [aN]
Final mix: [a0][a1]...[aN] amix=inputs=N:normalize=0The video stream is copied (-c:v copy), no re-encoding, while all audio tracks are mixed and muxed in.
There are still edge cases. For example, blob: and data: media URLs are intentionally skipped by the server-side preprocessing path, and dynamically generated media that never exposes a fetchable URL can't be reconstructed this way.
Determinism Is a Full-Time Job
You might think that once you control time and rendering, you're done. You are not done. The browser has many ways to be non-deterministic.
OffscreenCanvas, for example, lets pages render on a web worker thread that bypasses our main-thread capture pipeline. So we disable it:
// deterministic-safety-shim.js
Object.defineProperty(window, 'OffscreenCanvas', { value: undefined, writable: false });
Object.defineProperty(
HTMLCanvasElement.prototype,
'transferControlToOffscreen',
{ value: undefined, writable: false }
);Since we're rendering arbitrary URLs in a headless browser on our cloud infrastructure, subresource requests are validated against SSRF patterns: cloud metadata endpoints, private IPs, localhost, and internal hostnames. For server-side media fetches, redirect targets are also re-validated (video preprocess follows multiple hops; audio is more conservative).
The service itself is intentionally single-flight: one active render at a time in the app, and concurrency set to 1. Video rendering is resource-hungry enough that isolation is worth more than throughput: Chrome uses gigabytes of RAM, FFmpeg maxes out CPU, and memory pressure causes frame corruption.
Standing on Shoulders: WebVideoCreator
We didn't start from scratch. Our renderer is heavily inspired by WebVideoCreator, an open-source project by Vinlic that pioneered the core idea of time virtualization + BeginFrame capture in headless Chrome. That project deserves real credit. The fundamental insight that you could monkey-patch browser time APIs and combine that with Chrome's deterministic rendering mode to capture arbitrary web pages frame-by-frame is genuinely clever, and we would have spent significantly longer getting here without it.
Where we diverged: WebVideoCreator was built against the old headless mode on the main chrome binary. Since then, Chrome split the old headless mode into a separate chrome-headless-shell binary with a different API surface (starting with Chrome 120, fully removed from the main binary in Chrome 132). We also needed tighter integration with our cloud infrastructure (Cloud Run, GCS uploads, Datadog tracing), stricter security (SSRF protection for rendering untrusted URLs), and more control over the video element pipeline and audio extraction. So we rewrote it in TypeScript with modern Puppeteer and adapted the architecture for our deployment model.
We're planning to open-source our implementation. The techniques here (time virtualization, BeginFrame capture, the video element workaround pipeline) are useful to anyone building programmatic video from web content, and the ecosystem will be better for having more options. Stay tuned.
If you're into deterministic browser capture, low-level Chrome APIs, and making FFmpeg do fun things, we're hiring.