
In early September we set out to simplify and stabilize Replit. "There's no better time to cut back than when you're growing," said Amjad. We've been working on this project in earnest for 10 weeks now. When you're in the thick of improving things all you can see is what remains undone, so it's good to look at how far you've come!
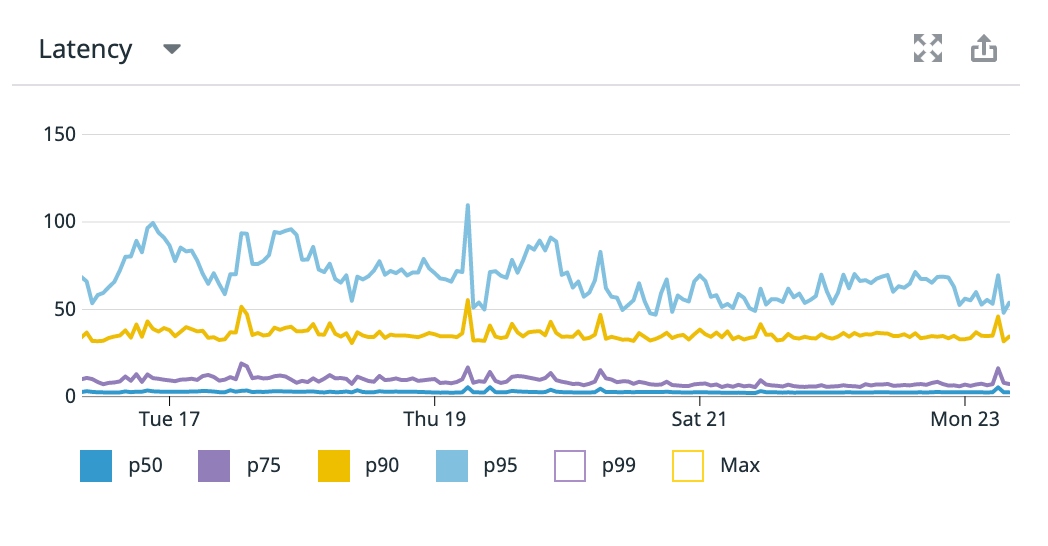
Towards the end of September, we had multiple incidents where latency across Replit rose to unacceptable levels (the median request to the site could take 10 seconds). We were embarrassed. We had embarked on a stability sprint and the site felt worse. Increased load on Replit and in particular our legacy Classroom product seemed to have tipped us over a cliff. We added followers to our Postgres database and allowed people to export their classrooms into the much-more-stable Teams for Education, but it wasn't enough. We wanted to stop reacting to growth and put the web app on a solid footing. So we took the time to evenly distribute Postgres connections across all follower databases, cached the most frequently queried objects, and put rate limits in place. Since then latency has looked flat and boring.
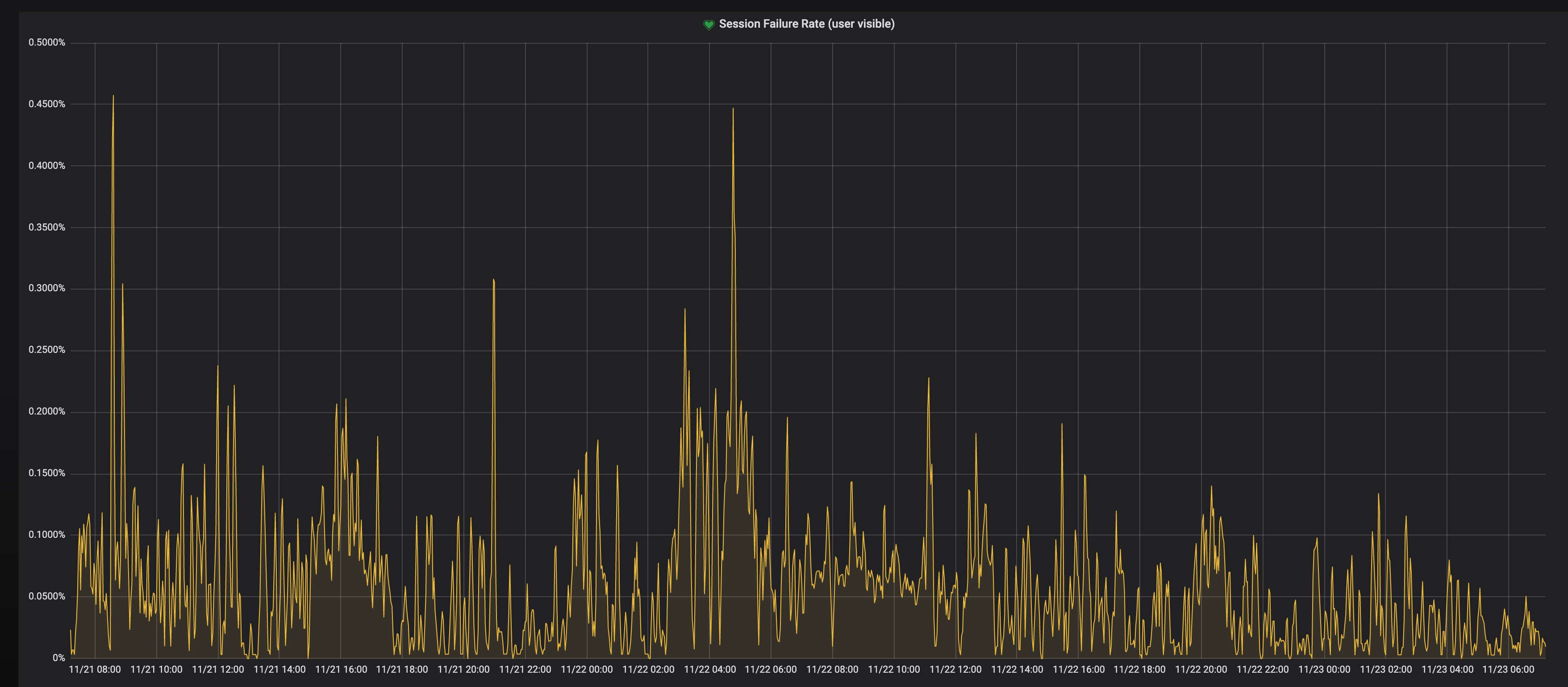
When you visit a repl, your browser opens a websocket connection to a running container. Despite this being a crucial step (if you can't connect to the container, you can't do much of anything in a repl), we had never measured how often it succeeded. The actual numbers weren't great but also weren't dire: if you tried to connect to the Replit backend in September, you would succeed 97% of the time (1 out of every 33 times you simply wouldn't connect). Now connections succeed 99.5% of the time (you'll only fail to connect 1 out of every 200 times).
Surprisingly, the 99th percentile time for loading a repl went from 2+ minutes to between 10 and 15 seconds! It turns out that a common failure mode was when a repl was running on a machine scheduled to shut down. It was taking over 30 seconds for a machine to destroy all its containers! And sometimes the machine couldn't cleanly destroy all its containers, meaning the system-wide locks for those repls would outlive their containers, causing all sorts of problems. Once we sped up shutdown, people stopped having to wait 30-plus seconds to be able to connect to certain repls, and a bunch of our metrics started looking dramatically better.
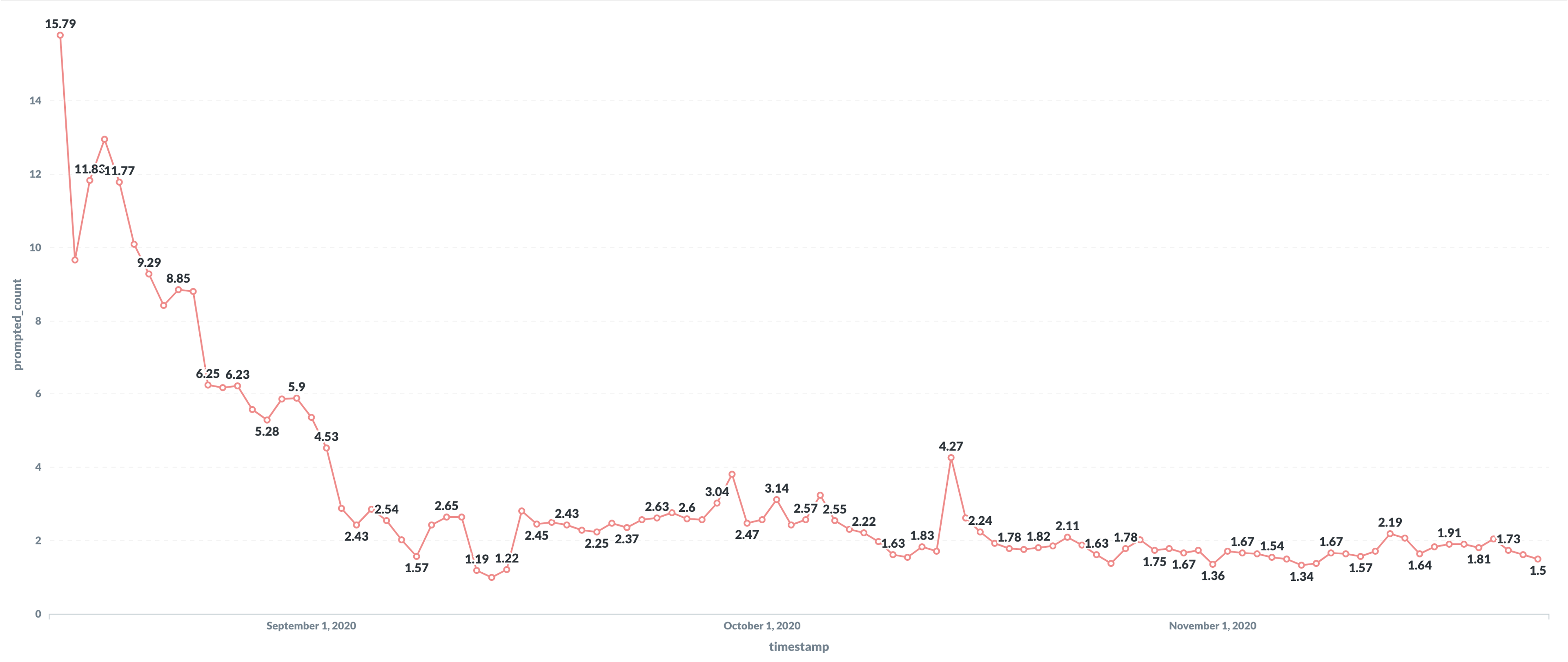
If the websocket connection between the browser and the container closes for any reason, the repl will reconnect automatically. Back in September, 2.81% of reconnections would lead to a prompt asking you whether you wanted to keep your local changes or the server changes. That's a stressful prompt to get! It means Replit cannot automatically reconcile the local edits you've made to your repl with what's in the container. In August it was much higher. We've brought that prompt down to 1.5% of reconnections and are cooking up a fix for a particularly gnarly case that should drop the prompt rate near zero.
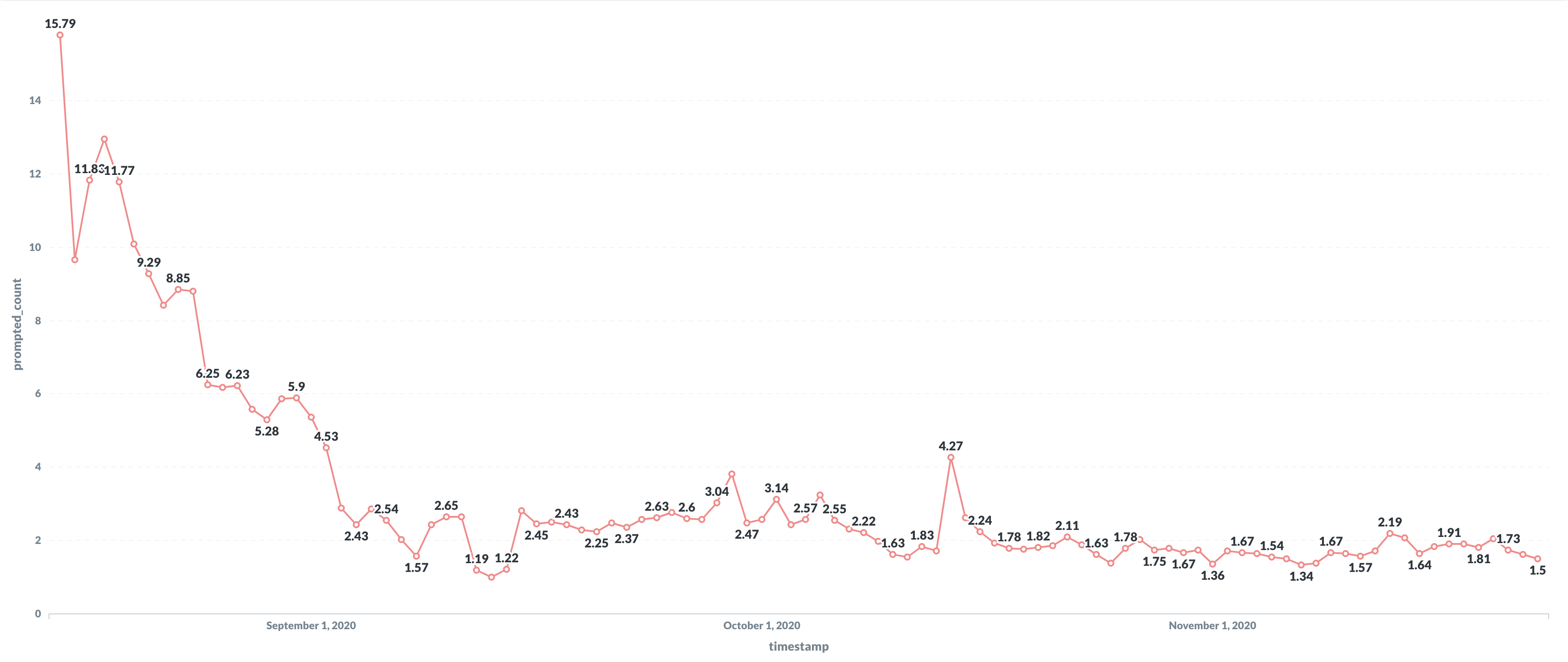
We sincerely hope all of Replit feels faster and more reliable than it did in September. If it doesn't, please let us know! On the surface, this has been a pretty boring story: we set out to make Replit more stable and we did. The larger lesson, though, is that when you're growing rapidly, it's not enough to fix the symptoms right in front of you. You've got to find the biggest bottleneck and either eliminate it or kick it so far down the road that you won't notice it until usage has grown another 100x.