We at Replit pride ourselves on a snappy user experience. When I noticed our Universal Package Manager taking a slow ~200 ms to do even the most trivial operations, I took a look.
Some context: Universal Package Manager, or UPM, is a package manager that works for a number of Replit-supported programming languages. It allows the Replit infrastructure to work with the same API, regardless of the language for the packaging aspect of the system.
One important feature it offers is package guessing: the ability to look at your source files and figure out what packages you need automatically. However, since the package guessing operation has to happen when you click the Run button, it ever so slightly slows down the running of your code.
I discovered that generally, regardless of which UPM operation was executed, it took at least ~200 ms for it to do the work. Given that UPM is written in Go — a language with a reputation for being fast — this was surprising.
If in a Python Repl you executed UPM using the "time" program:
time upm
You would have seen something like:
Usage:
upm [command]
.
.
.
real 0m0.277s
user 0m0.228s
sys 0m0.094s
Note: the numbers above are out of date, since the problem has been fixed
It was taking 277 ms to do something trivial, like printing out the usage information.
I can make a Python program, a generally slower language, and print out the same text in less time.
So I started digging.
Manual time measurement
To figure out what is making a program slow, you can time the program's steps and single out the slowest step. For example, if the program's code was:
step1()
step2()
step2()
You'd add some time measurement code like:
step1Start := time.Now()
step1()
step1Duration := time.Since(step1Start)
step2Start := time.Now()
step2()
step2Duration := time.Since(step2Start)
step3Start := time.Now()
step3()
step3Duration := time.Since(step3Start)
fmt.Printf("It took %dms to do step 1\n", step1Duration.Milliseconds())
fmt.Printf("It took %dms to do step 2\n", step2Duration.Milliseconds())
fmt.Printf("It took %dms to do step 3\n", step3Duration.Milliseconds())
Usually, one of the steps would be disproportionately large, and we could then drill into that step and follow the same procedure for its substeps to figure out what to optimize.
The entrypoint to UPM looks like this:
package main
import "github.com/replit/upm/internal/cli"
// Main entry point for the UPM binary.
func main() {
cli.DoCLI()
}
I added the timer to the top level main() function:
package main
import (
"github.com/replit/upm/internal/cli"
"time"
"fmt"
)
// Main entry point for the UPM binary.
func main() {
start := time.Now()
cli.DoCLI()
duration := time.Since(start)
fmt.Printf("UPM took %dms\n", duration.Milliseconds())
}
However, when I ran this version of UPM, it reported a time between 1-5 milliseconds! This means the program spent the majority of its time just getting loaded. ~200ms before even reaching the first line of code! What's going on? Is Go slow?
Sanity check
When I get an unexpected result, I like to double-check to make sure it’s not user error. I made a bare-bones hello world Go program:
package main
import "fmt"
func main() {
fmt.Println("Hello, world!")
}
Then, I compiled it into a binary: go build main.go and ran it with time:
$ time ./main
Hello, world!
real 0m0.011s
user 0m0.001s
sys 0m0.010s
11ms. So Go is still fast. Phew!
The bug sandwich
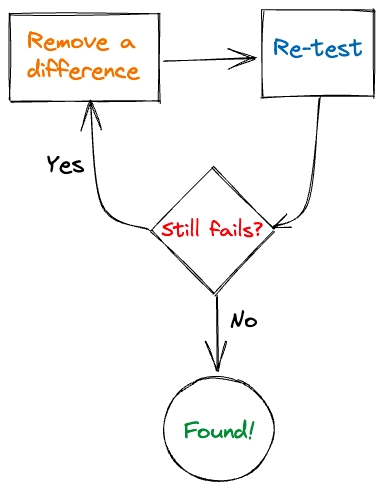
Now, although I have no idea what the cause of the slow down is, I have a way to narrow it down using a debugging technique I call the bug sandwich. I learned this technique as delta debugging from Why Programs Fail. In order to use it, you need a good test case and a bad test case. For me, the good test case is the hello world program: it starts fast. The bad test case is the UPM program: it starts slow. The premise of the bug sandwich is that there is one key failure inducing difference between the two that makes the good one good, and the bad one bad.
Suppose you can identify a set of differences D between the good case G and the bad case B.
The procedure is thus:
- Take one difference from the set D and remove it by making that part of B the same as G.
- Re-test B.
- If B no longer exhibits the failing behavior, then the failure inducing difference is the one you just removed. If this difference is small enough to tell you what the issue is, you are done.
- If the difference is too large to point you to the problem, undo the change in step 1 and try again with a smaller difference.
- If you get a different result entirely, undo the change in step 1 and try again with a smaller or another difference.
- Else repeat the above steps until you find it.
In practice, you can slice up the set of differences in many different ways. If there's a lot of source code, you can use a divide-and-conquer technique.
Step 1
Starting with the entrypoint of UPM:
package main
import "github.com/replit/upm/internal/cli"
// Main entry point for the UPM binary.
func main() {
cli.DoCLI()
}
Another sanity check (one can never do too many): I replaced this code with the hello world program and re-compiled UPM. I ran it again, and it was fast.
Step 2
The difference I chose to remove was too large: I removed all the differences. So, I reverted UPM back to normal and tried to remove a smaller difference. There were only 2 candidates– the line:
import "github.com/replit/upm/internal/cli"
or the line:
cli.DoCLI()
Removing one of the lines requires the removal of the other due to Go's static check rules. So...
package main
// Main entry point for the UPM binary.
func main() {
}
Re-compiled. Ran. Still fast. Revert.
Step 3
We needed to drill into github.com/replit/upm/internal/cli. Its source code can be found in cli.go.
Notably, this file contains a DoCLI() function that we called from the main() function. It contains a lot of code, so I won't show it here. I emptied this function, and the Go linter asked me to remove some unused imports.
Re-compiled. Ran. It was starting up slow. Interesting! This program was by definition not doing anything material, and yet was still slow. The only logical conclusion I could come up with is that just by importing a certain Go library, it was able to slow the program's startup time. And the only import left was github.com/replit/upm/internal/util.
Step 4
I removed the import for github.com/replit/upm/internal/util. The Go compiler led me to remove the last reference to that module. Re-compile. Ran. Still slow...
Step 5
There was a cmds.go file in the same directory that imported some other packages as well. So I got rid of those and commented out the entire file except for the initial package statement.
Re-compiled. Ran. Now it was fast! We were getting closer. This meant that one of the items in this list of imports was making things slow. I noticed that one of those imports was github.com/replit/upm/internal/backends.
This gave me a hunch.
Revert.
Step 6
UPM supports several programming language backends. In the Python backend, we do something big-brain: there's a programmatically generated pypi_map.gen.go file that is 25MB large.
It contains data used for the Python package guesser. Because Python packages' import names don't necessarily match the package names, we have a job that tests installing each of the top 50K packages on pypi to figure out what their import names are. The results of those tests go into this generated file.
Hypothesis: the largeness of this file was making the program start up slowly, presumably because Go wanted to load all those entries into memory at startup time. So I tested it. I opened up the file, and it took quite a bit of time to open because of its size.
There were 3 variables in this file, and each one was a map literal containing many entries. I emptied each map.
Re-compiled. Ran. It's fast! Bingo!
Aftermath
At this point, we still had to solve the problem. But the root cause was found, namely that writing very large map literals in a Go file caused it to be loaded into memory eagerly at the program's initialization, and that can be slow.
There are different ways to solve this:
- Wrap these maps inside functions, which initialize the maps only when they are called. This is called lazy loading.
- Externalize them into a lightweight database like SQLite so that all of the data doesn't have to be loaded into memory at the same time.
I ultimately chose #2 and it helped reduce UPM's run time by ~200ms, speeding up the Run button by the same amount.
Lessons learned
Reflecting on this journey, here are some of my takeaways:
- Even if you have no clue what the problem is, you can still solve it. There are ways.
- Bug sandwich is a yummy technique. Give it a try some time.
- Golang is not slow.
- With performance work, understanding what’s going on is 90% of the battle.
Careers at Replit
If you are looking for an interesting place to work where you can solve tough challenges like this one, Replit is hiring.